基于pyspark和hive的酒店数据分析系统_毕设
舟率率 1/4/2026 pythonscaladjango
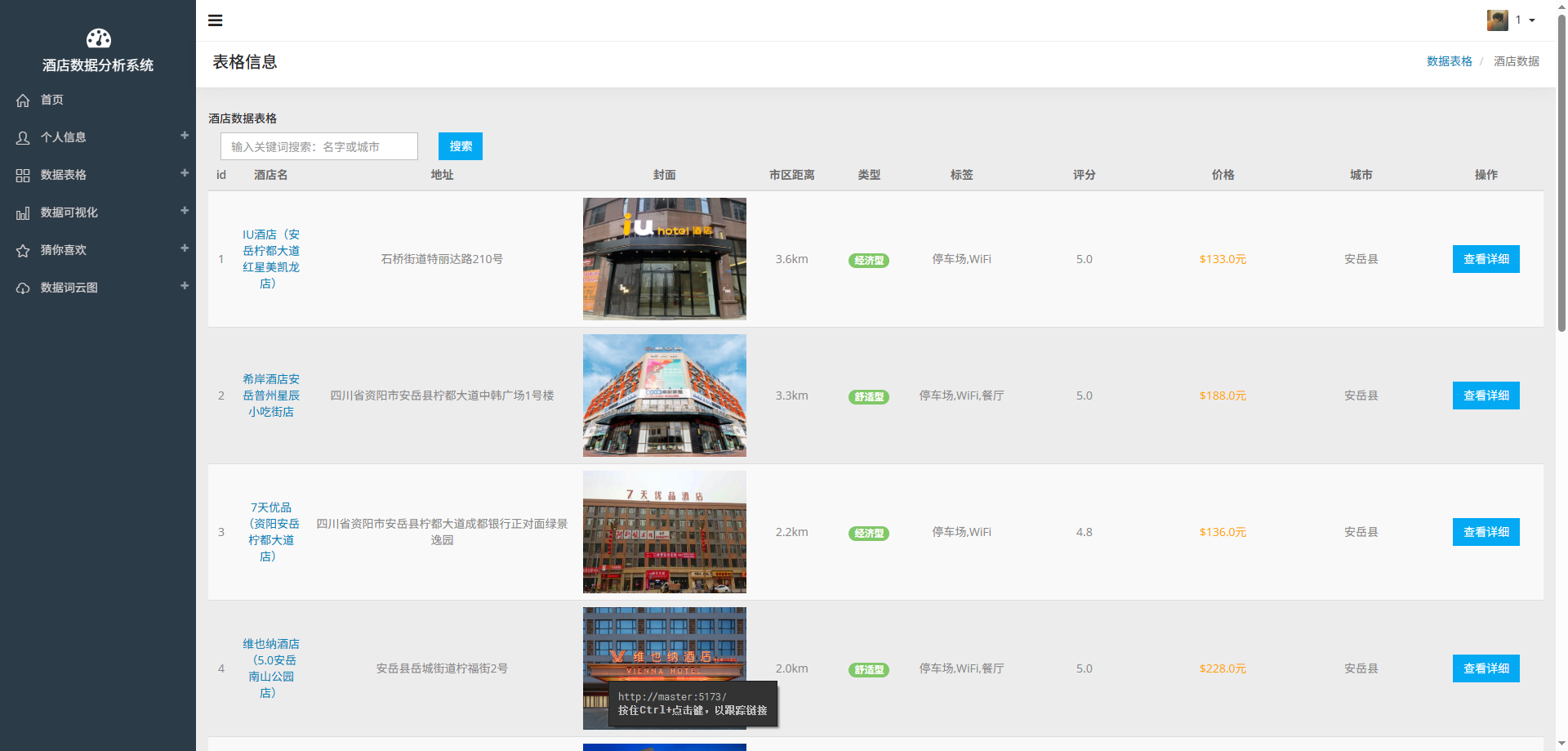
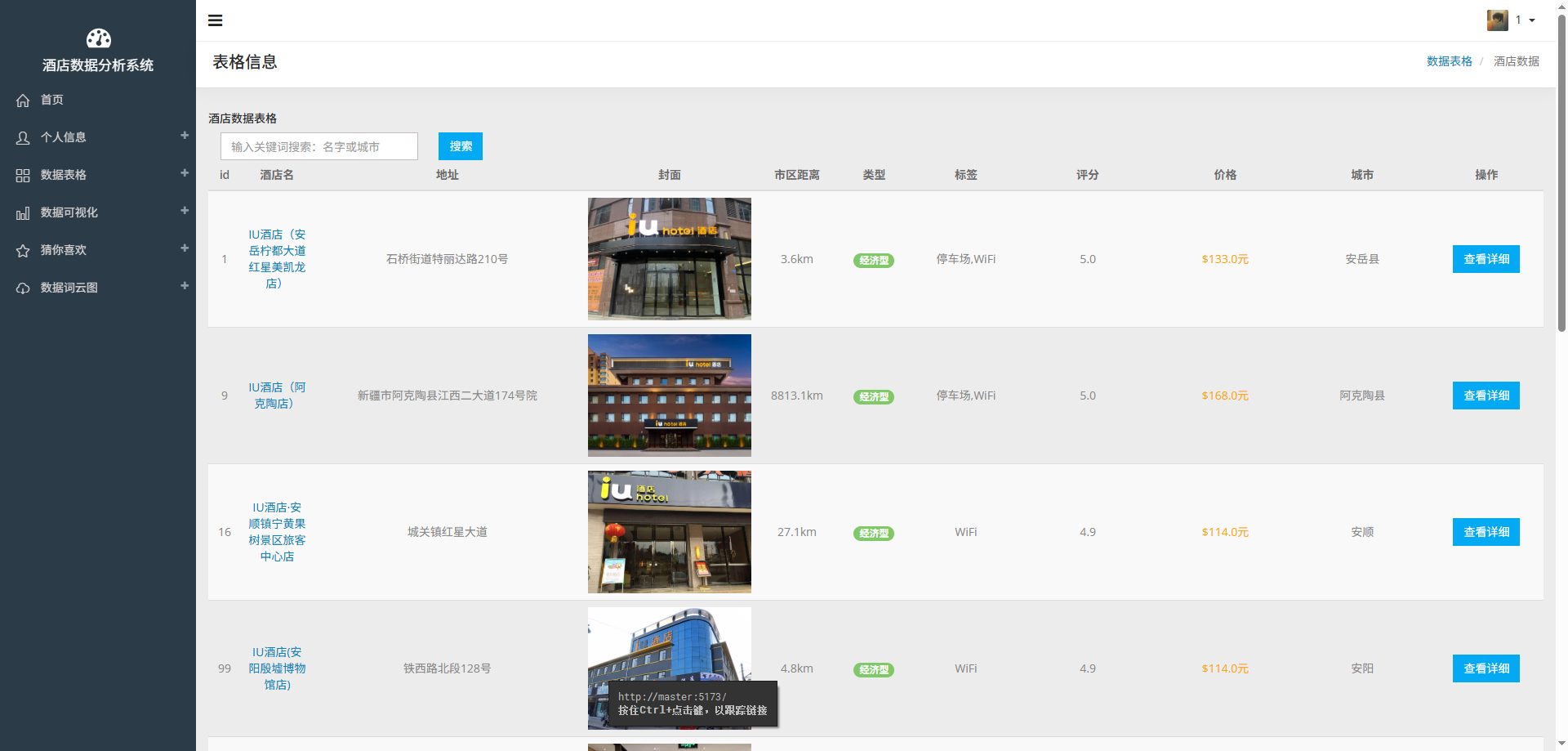
# 项目概况
# 数据类型
酒店数据
# 开发环境
centos7
# 软件版本
python3.8.18、hadoop3.2.0、spark3.1.2、hive3.1.2、mysql8.0.41、jdk8
# 开发语言
python
# 开发流程
数据上传(hdfs)->数据处理(spark)->处理结果(hive)->数据分析(spark)->数据存储(mysql)->后端(django)->前端(html+js+css)
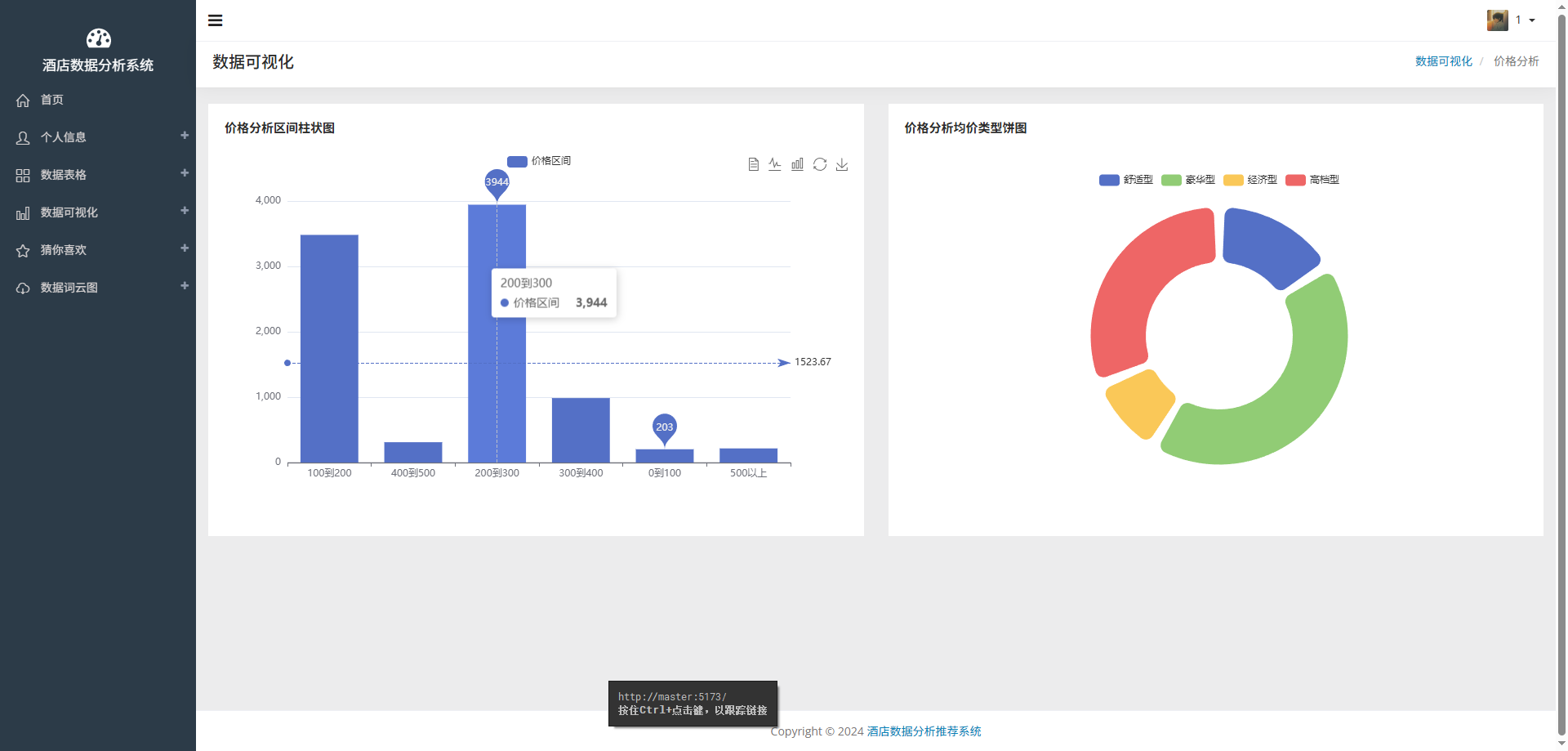
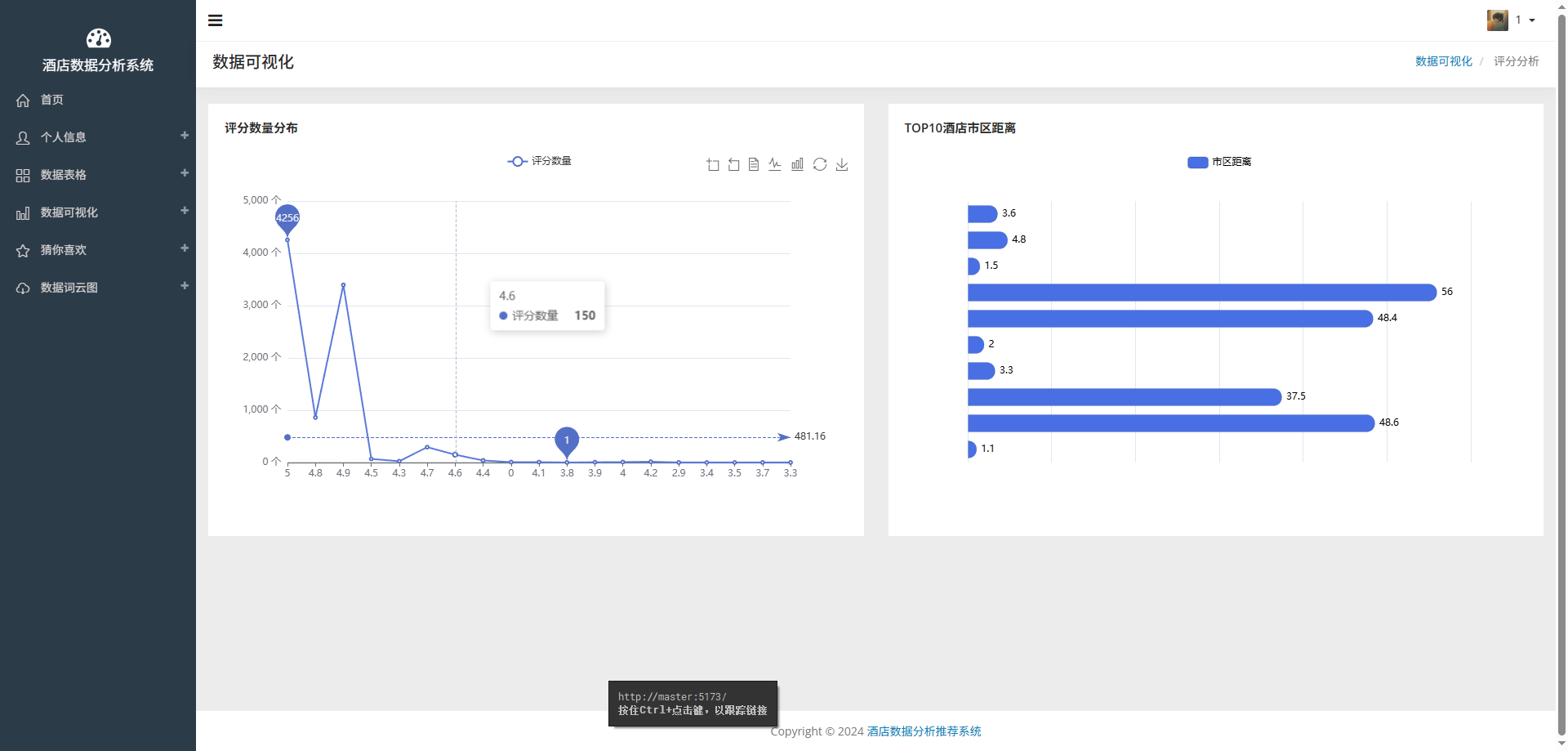
# 可视化图表
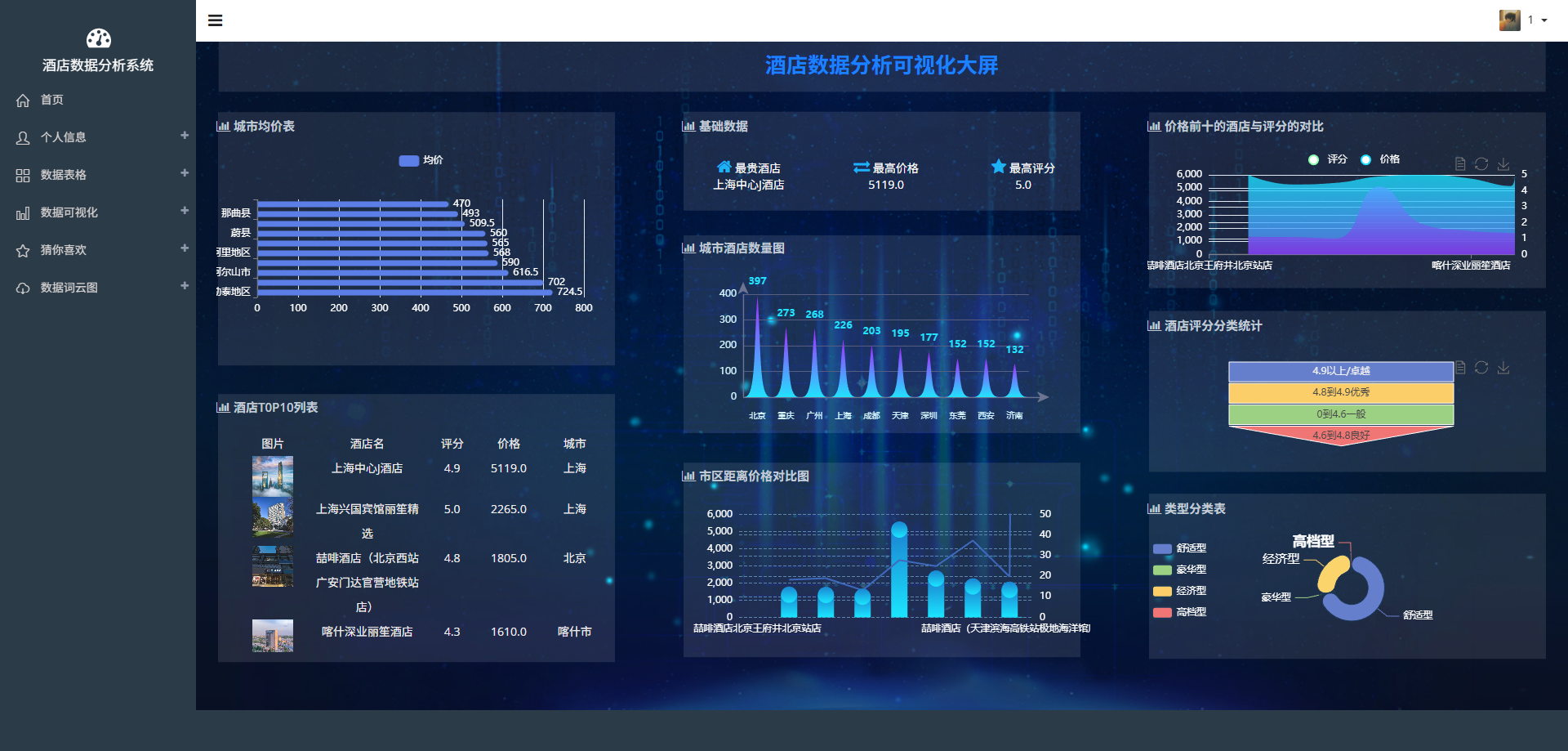
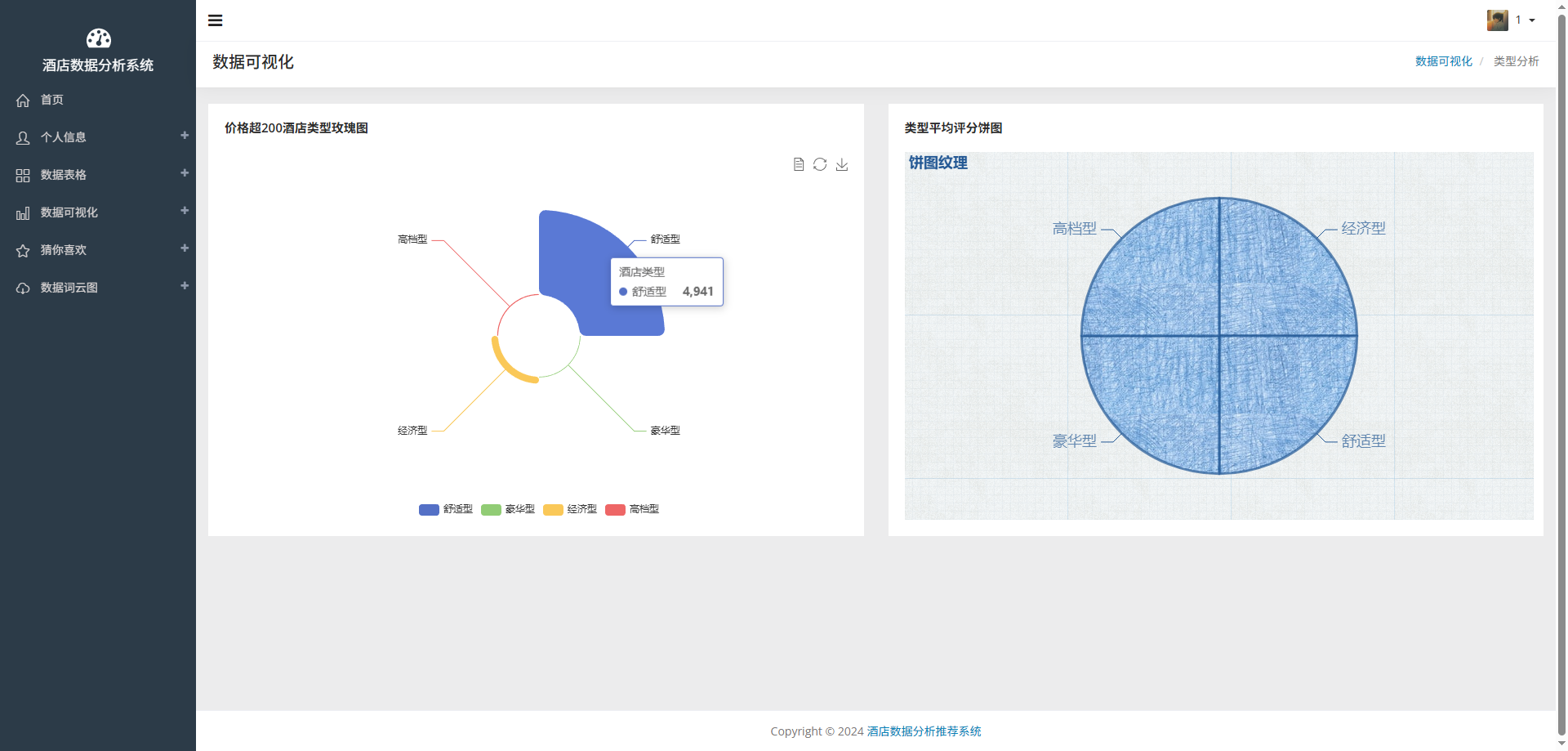
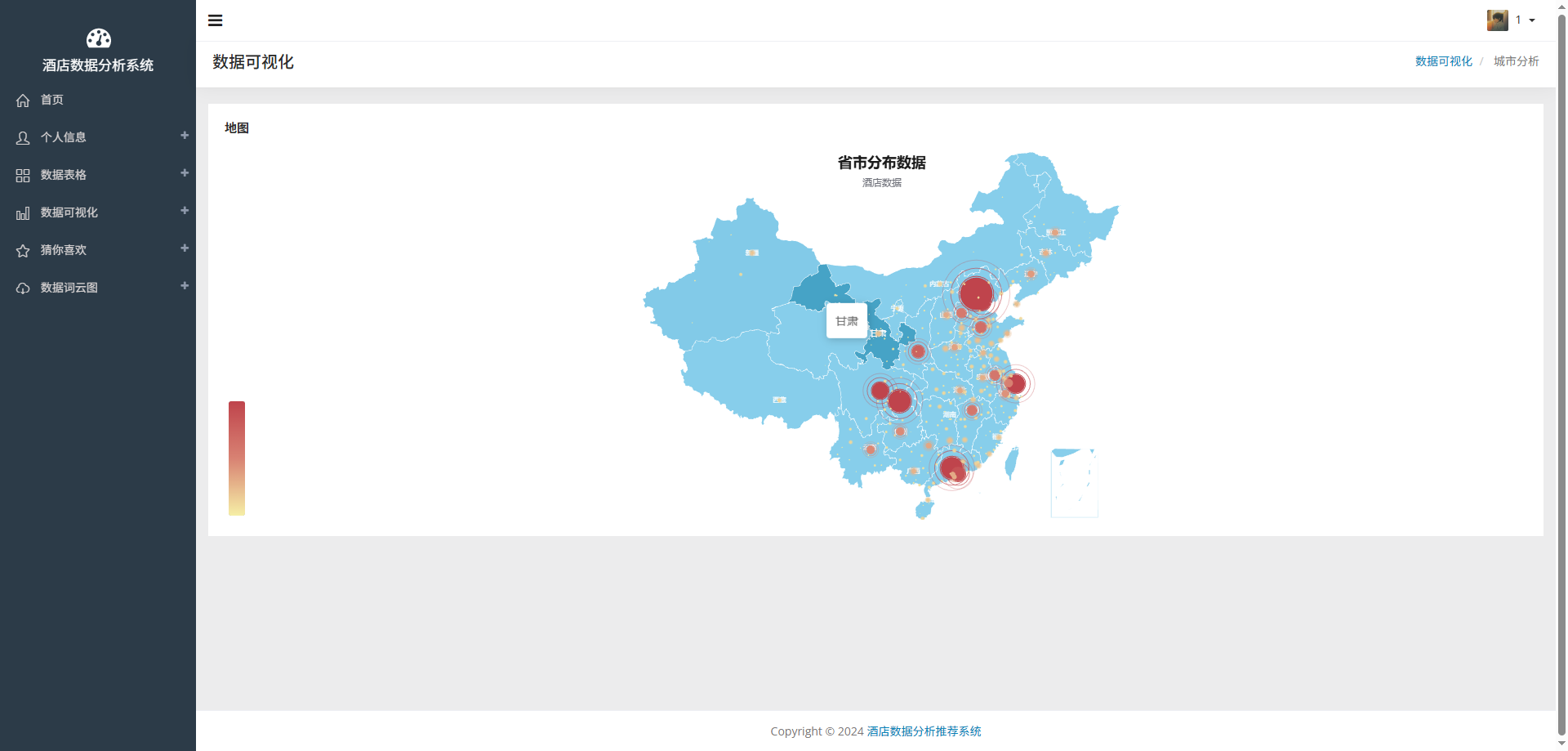
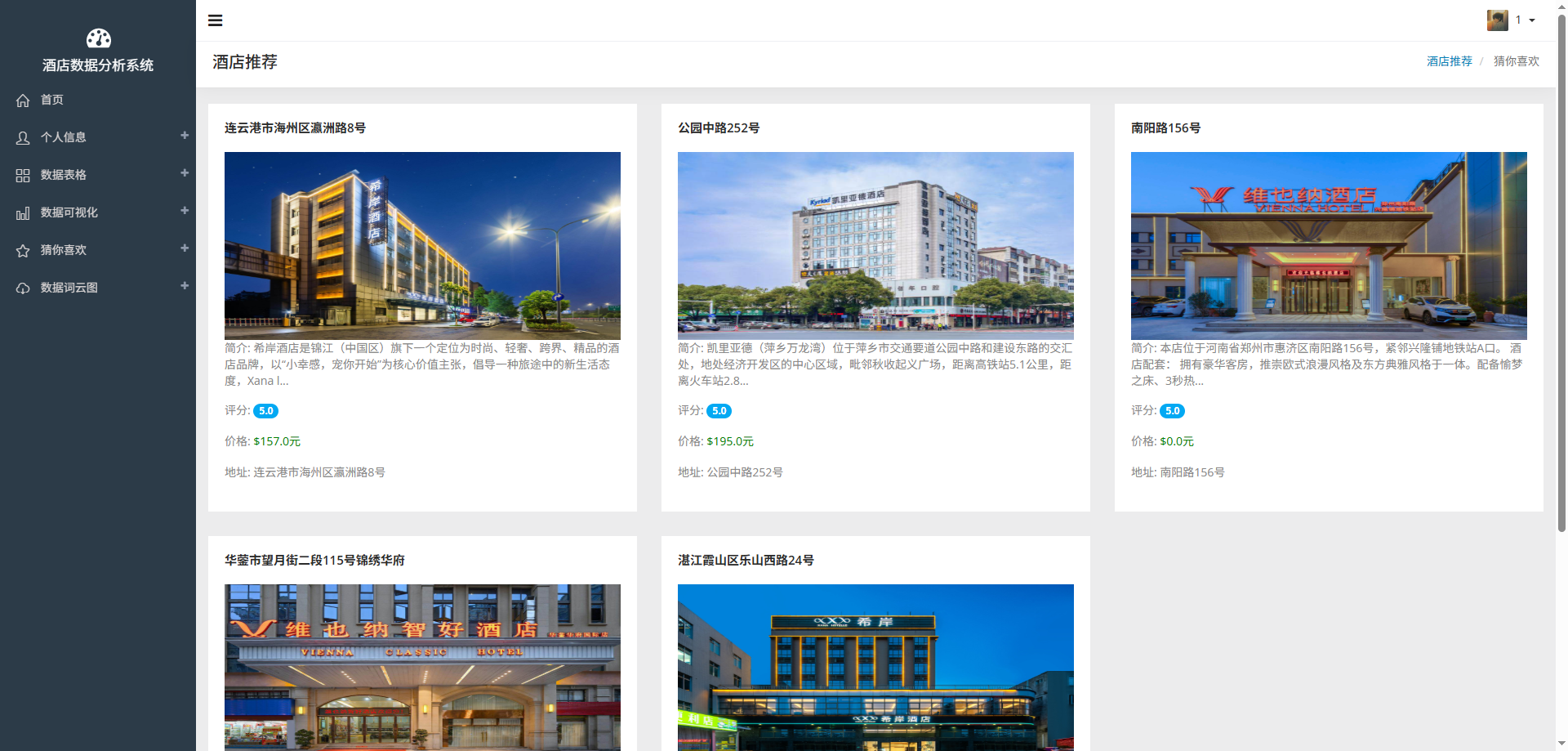
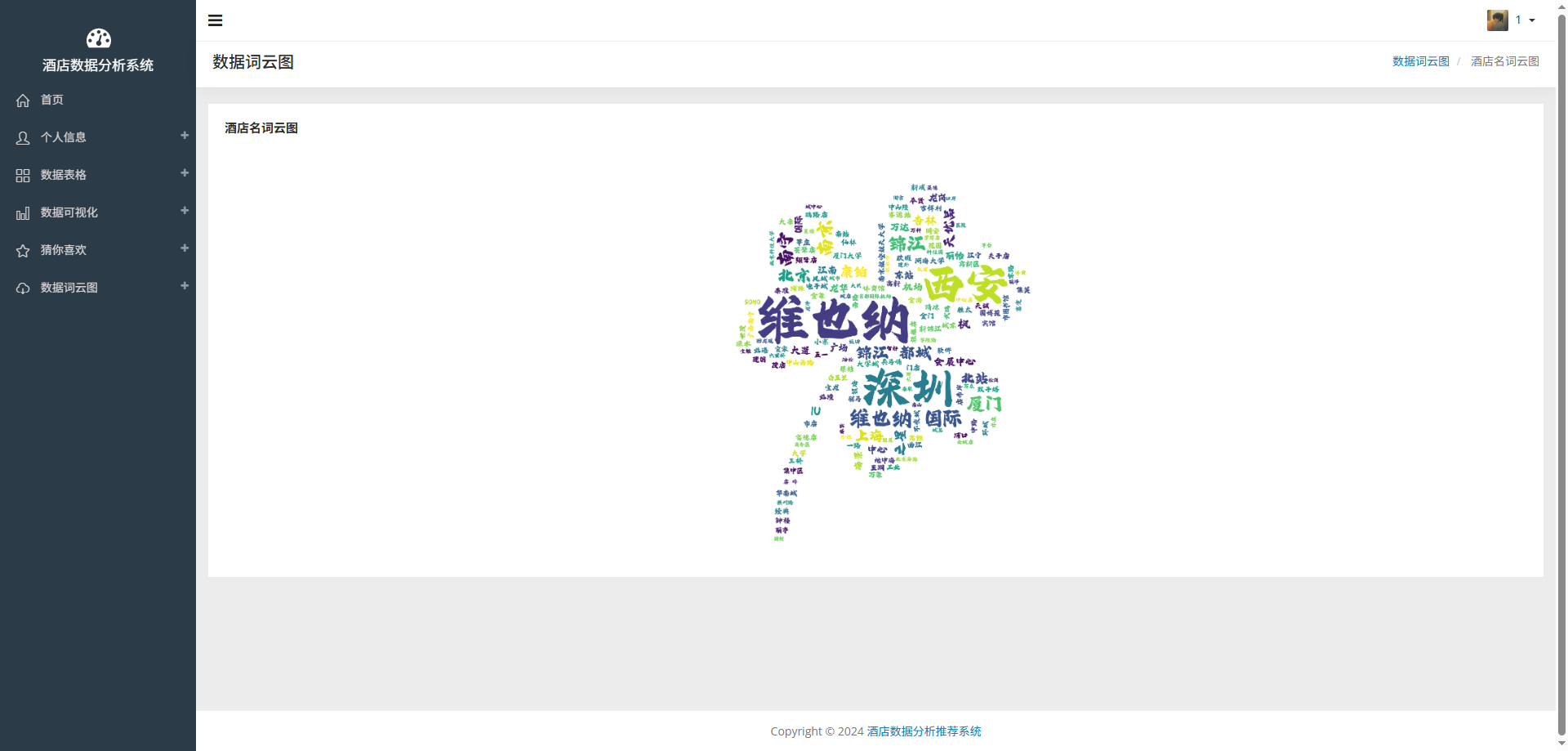
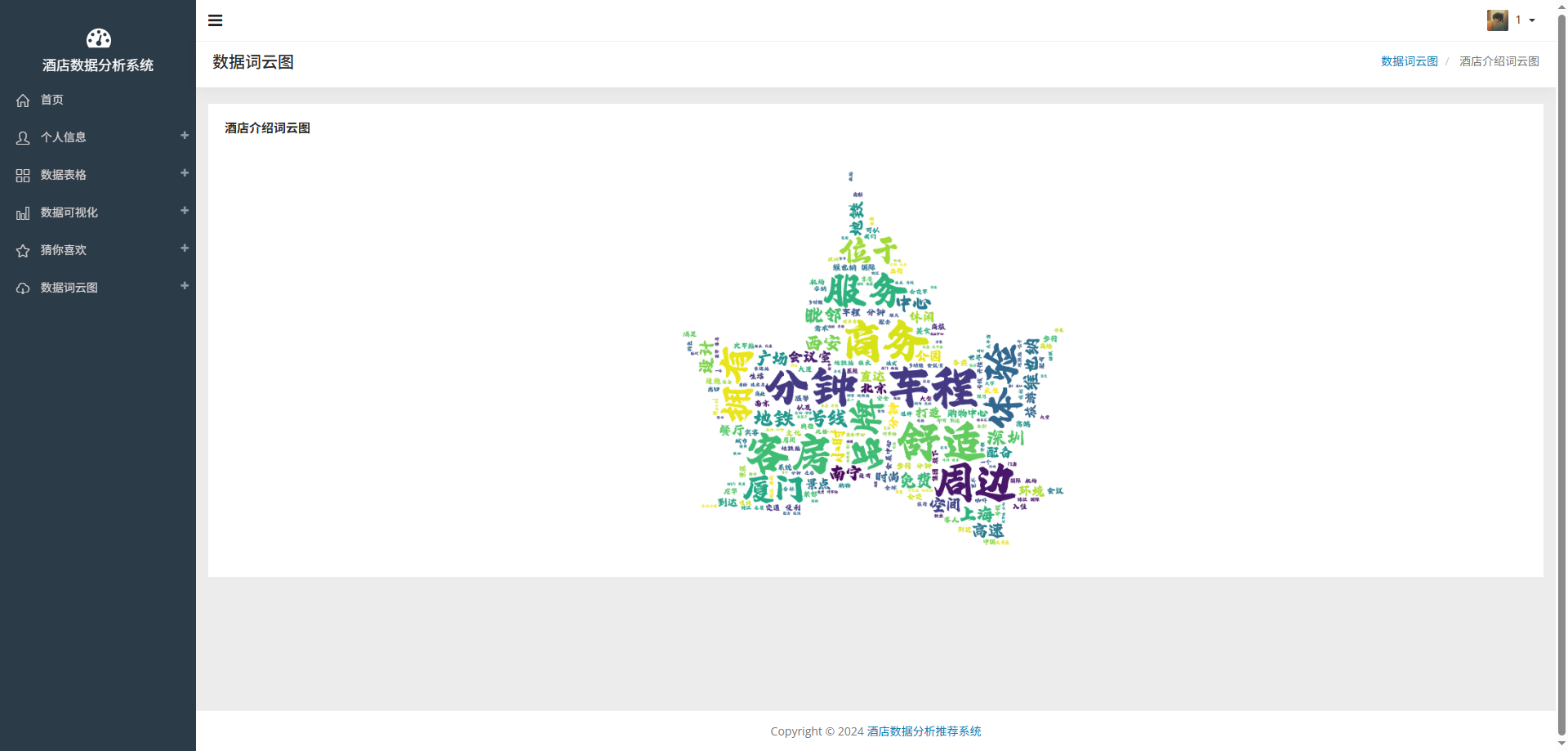
# 操作步骤
# python安装包
pip3 install django==4.2.11 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install djangorestframework==3.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install django-simpleui==2025.6.24 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install pyhive==0.7.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install thrift==0.21.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install thrift-sasl==0.4.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install DBUtils==1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install pandas==2.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install numpy==1.24.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install scikit-learn==1.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install pymysql==1.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# ubuntu 还需要安装以下包
# sudo apt update && sudo apt install -y build-essential python3-dev pkg-config libmysqlclient-dev
pip3 install mysqlclient==2.2.7 -i https://pypi.tuna.tsinghua.edu.cn/simple
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
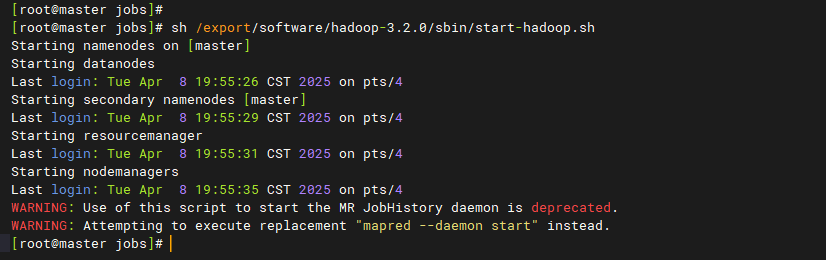
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 启动MySQL
# 查看mysql是否启动 启动命令: systemctl start mysqld.service
systemctl status mysqld.service
# 进入mysql终端
mysql -uroot -p123456
1
2
3
4
5
6
2
3
4
5
6
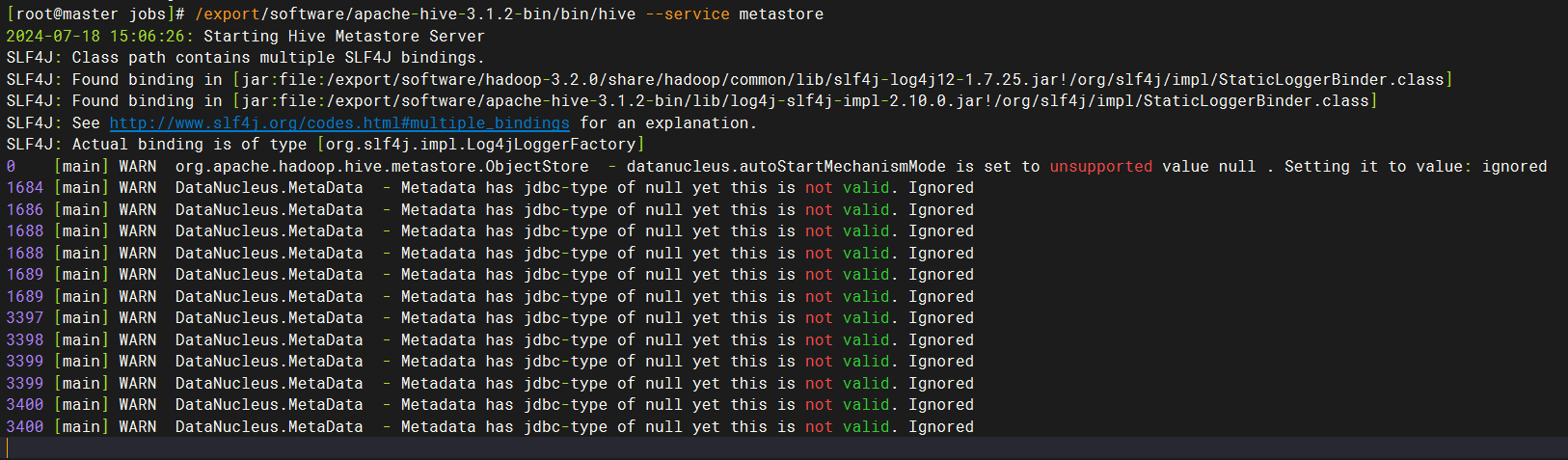
# 启动hive
# 在第一个窗口中,执行后等待10-20秒
/export/software/apache-hive-3.1.2-bin/bin/hive --service metastore
# 在第二个窗口中,执行后等待10-20秒
/export/software/apache-hive-3.1.2-bin/bin/hive --service hiveserver2
# 连接进入hive终端命令如下:
# /export/software/apache-hive-3.1.2-bin/bin/beeline -u jdbc:hive2://master:10000 -n root
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10

# 上传代码及文件
mkdir -p /data/jobs/project/
cd /data/jobs/project/
# 解压缩
# 解压spark/目录下的 "realData.7z" 和 "temp1_unique.7z"
# 解压 "飞波正点体.7z"
# 解压成功后,上传整个project-pyspark-hotel-data-analysis文件夹
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# MySQL建表
cd /data/jobs/project/project-pyspark-hotel-data-analysis/
mysql -uroot -p123456 < hotelstore.sql
1
2
3
4
5
2
3
4
5
# 执行sparkFir.py
cd /data/jobs/project/project-pyspark-hotel-data-analysis/
spark-submit \
--master local[*] \
spark/sparkFir.py
1
2
3
4
5
6
7
2
3
4
5
6
7
# 执行sparkAna.py
cd /data/jobs/project/project-pyspark-hotel-data-analysis/
spark-submit \
--master local[*] \
spark/sparkAna.py
1
2
3
4
5
6
7
2
3
4
5
6
7
# 启动可视化
cd /data/jobs/project/project-pyspark-hotel-data-analysis/
python3 manage.py runserver master:5173
# 用户名:1
# 密码:1
1
2
3
4
5
6
7
2
3
4
5
6
7