基于flink的出租车数据分析系统_MySQL作为数据库
舟率率 11/7/2025 springbootmapreducejava
# 项目概况
# 数据类型
出租车数据
# 开发环境
centos7
# 软件版本
hadoop3.2.0、flink1.14.6、mysql5.7.38、jdk8
# 开发语言
Java、SQL
# 开发流程
数据上传(hdfs)->数据清洗(mapreduce)->数据分析(flink)->数据存储(mysql)->后端(springboot)->前端(html+js+css)
# 可视化图表
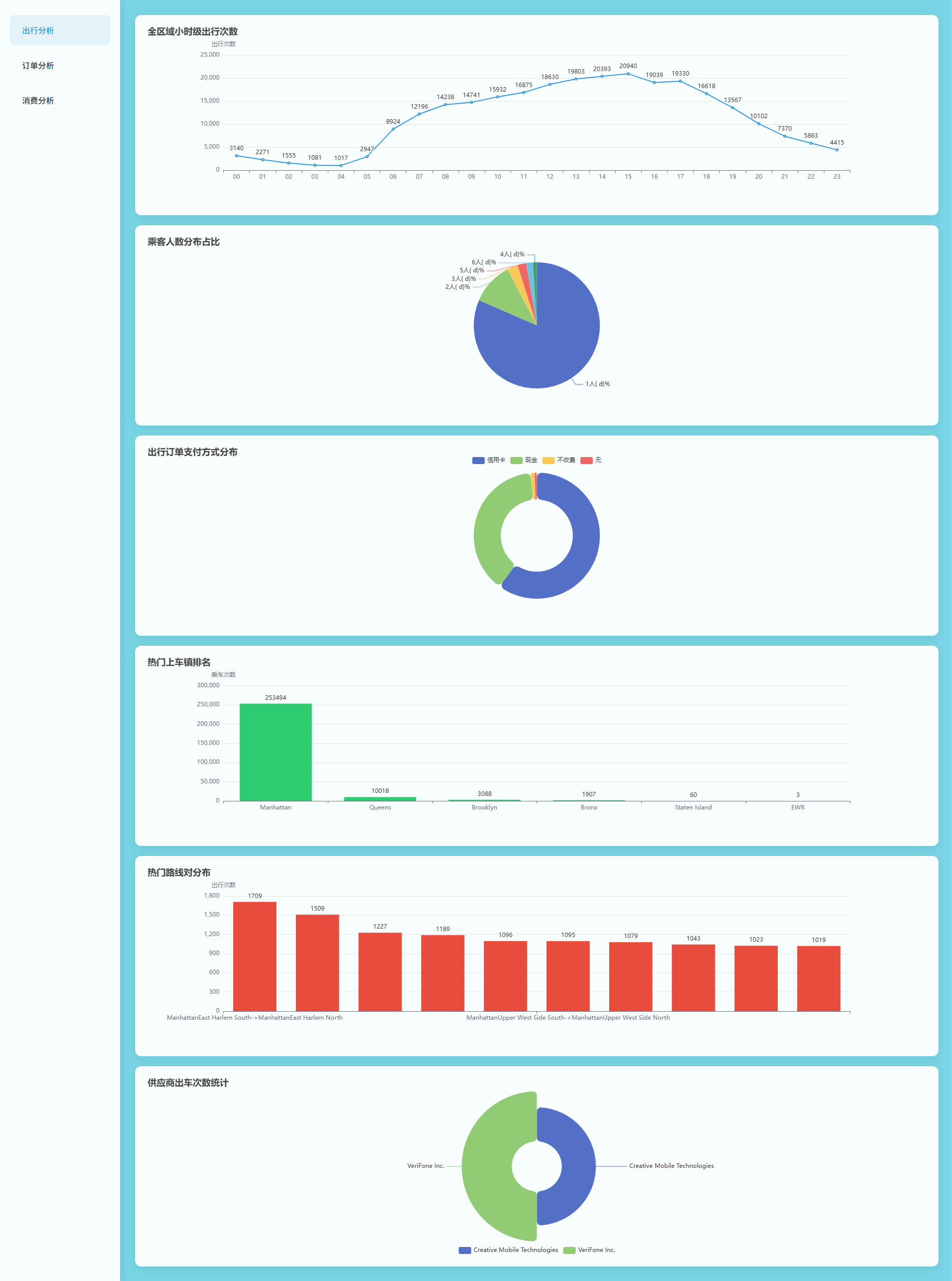
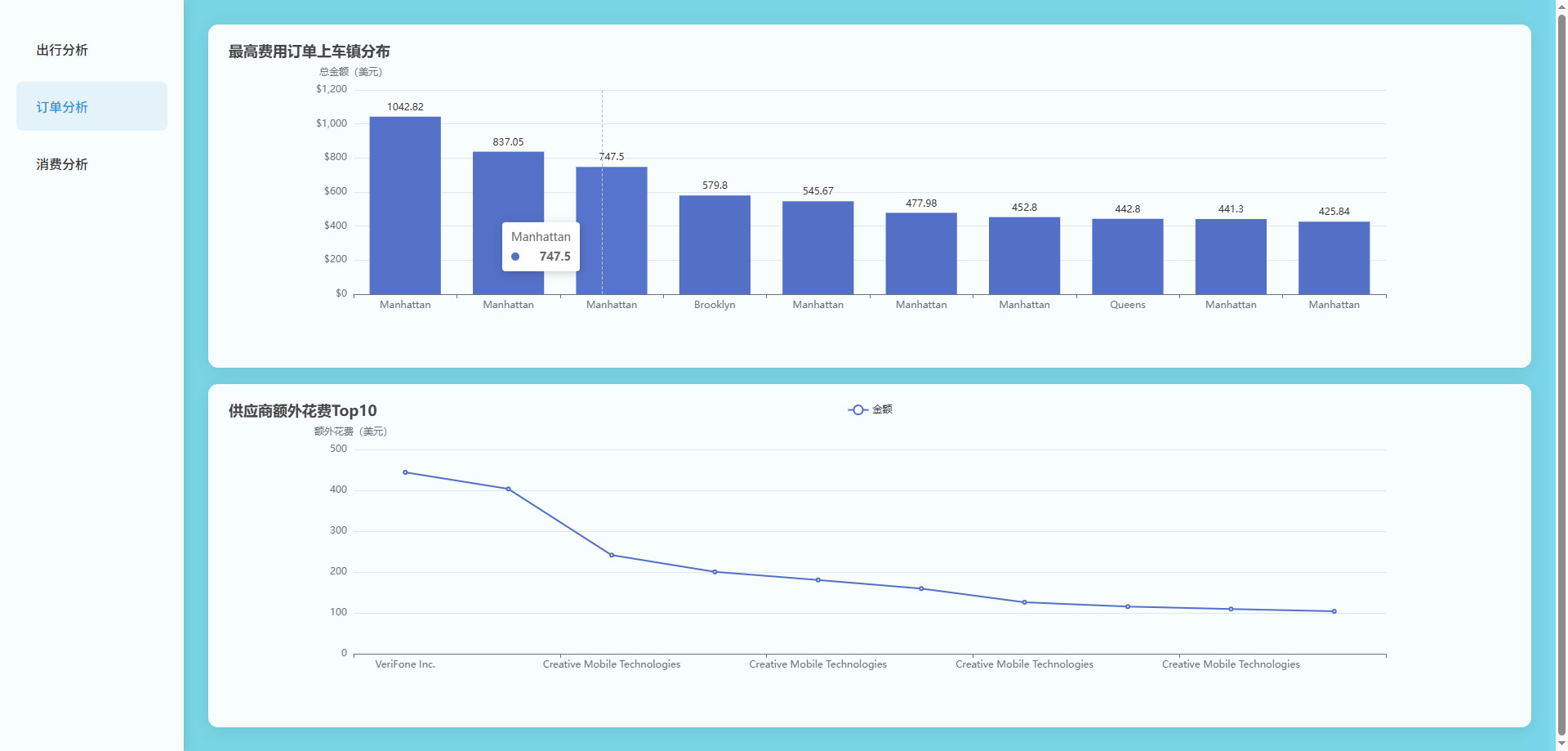
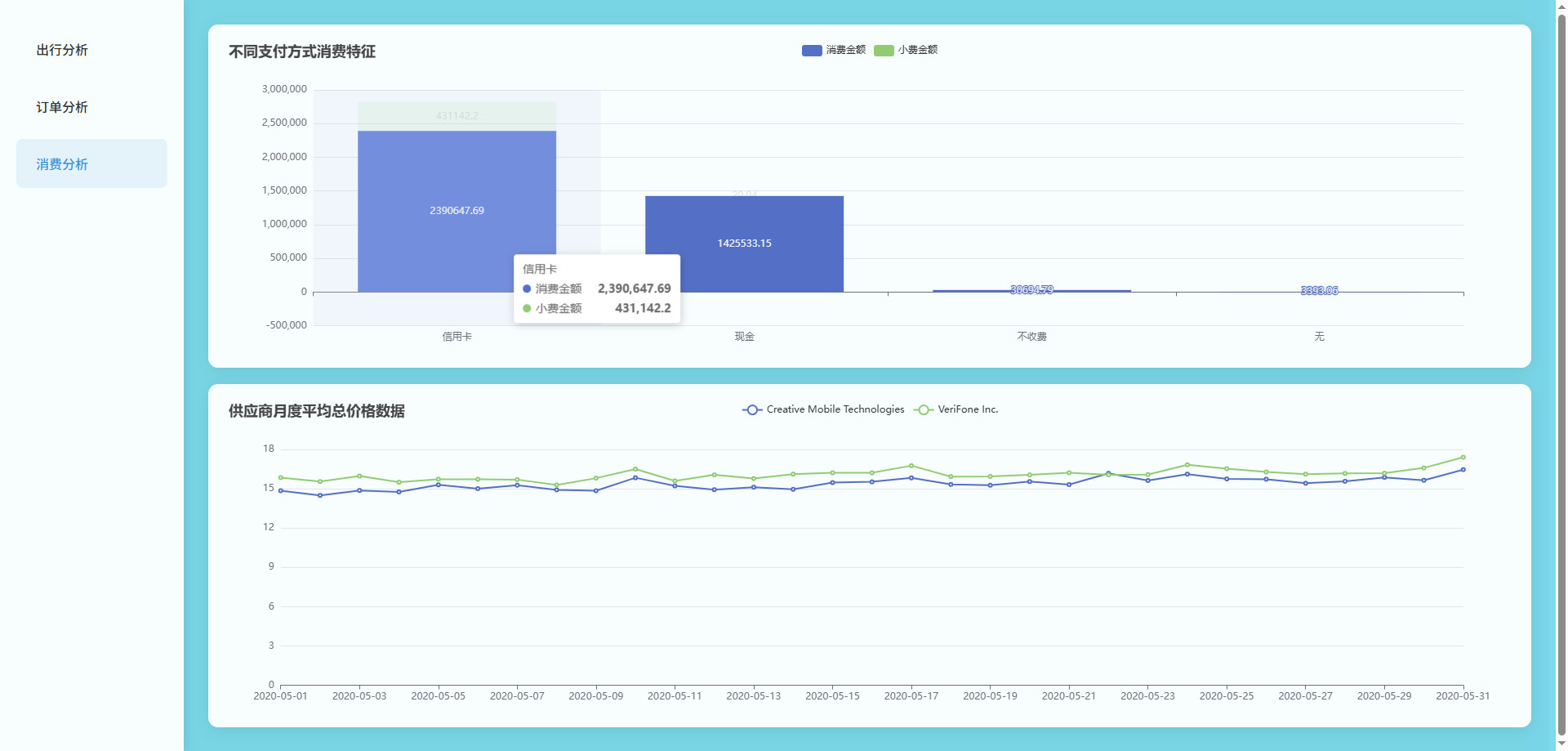
# 操作步骤
# 启动MySQL
# 查看mysql是否启动 启动命令: systemctl start mysqld.service
systemctl status mysqld.service
# 进入mysql终端
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
mysql -uroot -p123456
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 启动flink
# 启动
/export/software/flink-1.14.6/bin/start-cluster.sh
# 关闭
/export/software/flink-1.14.6/bin/stop-cluster.sh
1
2
3
4
5
6
7
2
3
4
5
6
7
# 准备目录
mkdir -p /data/jobs/project/
cd /data/jobs/project/
# 解压 "data" 目录下的 "data.7z" 压缩包
# 解压 "data" 目录下的 "data.7z" 压缩包
# 解压 "data" 目录下的 "data.7z" 压缩包
# 上传 "data" 目录下的 "yellow_tripdata_2020-05.csv" 文件
# 上传 "data" 目录下的 "taxi_zone_lookup.csv" 文件
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 上传文件到hdfs
cd /data/jobs/project/
hdfs dfs -rm -r /data/input/*
hdfs dfs -mkdir -p /data/input/taxi_zone_lookup/
hdfs dfs -mkdir -p /data/input/trip/
hdfs dfs -put taxi_zone_lookup.csv /data/input/taxi_zone_lookup/
hdfs dfs -ls /data/input/taxi_zone_lookup/
hdfs dfs -put yellow_tripdata_2020-05.csv /data/input/trip/
hdfs dfs -ls /data/input/trip/
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 数据清洗
cd /data/jobs/project/
# 打包 "数据预处理/mapreduce-job" 项目
# 打包命令: mvn clean package -DskipTests
# 上传 "数据预处理/mapreduce-job/target/" 目录下的 "mapreduce-job.jar" 文件
hadoop jar mapreduce-job.jar trip /data/input/trip/ /data/output/trip/
hdfs dfs -ls /data/output/trip/
hdfs dfs -cat /data/output/trip/part-r-00000 | head -10
hadoop jar mapreduce-job.jar location /data/input/taxi_zone_lookup/ /data/output/taxi_zone_lookup/
hdfs dfs -ls /data/output/taxi_zone_lookup/
hdfs dfs -cat /data/output/taxi_zone_lookup/part-r-00000 | head -10
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 创建MySQL表
cd /data/jobs/project/
# 上传 "mysql" 目录下的 "mysql.sql" 文件
# 请确认mysql服务已经启动了
# 快速执行.sql文件内的sql语句
mysql -uroot -p123456 < mysql.sql
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 数据分析
# 对 "project-hive-taxi-data-analysis" 目录下的项目 "flink-job" 进行打包
# 打包命令: mvn clean package -DskipTests
# 打包完成后,上传 "flink-job/target/" 目录下的 "flink-job.jar" 文件 到 "/data/jobs/project/" 目录
cd /data/jobs/project/
flink run -c org.example.Main flink-job.jar
# 若要在本地运行,需要删除以下内容:
# <exclude>org.apache.flink:flink-java</exclude>
# <exclude>org.apache.flink:flink-core</exclude>
# <exclude>org.apache.flink:flink-clients_${scala.version}</exclude>
# <exclude>org.apache.flink:flink-table-planner_${scala.version}</exclude>
# <exclude>org.apache.flink:flink-table-api-java-bridge_${scala.version}</exclude>
# <exclude>org.apache.flink:flink-table-common</exclude>
# <exclude>org.codehaus.janino:janino</exclude>
# <exclude>org.codehaus.janino:commons-compiler</exclude>
# <exclude>org.codehaus.commons-compiler:commons-compiler</exclude>
# <scope>${scope.type.provided}</scope>
# 若要在本地运行,需要修改以下内容:
# 改为本地文件路径
# hdfs://master:9000/data/output/trip/
# hdfs://master:9000/data/output/taxi_zone_lookup/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 启动可视化
cd /data/jobs/project/
# 打包 "project-hive-taxi-data-analysis" 项目
# 打包命令: mvn clean package -DskipTests
# 上传 "project-hive-taxi-data-analysis-1.0-SNAPSHOT.jar"
java -jar /data/jobs/project/project-hive-taxi-data-analysis-1.0-SNAPSHOT.jar org.example.taxi.Application
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9