基于Spark的厦门市市民球场处理与分析
舟率率 8/1/2025 pythonscala
原地址:https://dblab.xmu.edu.cn/blog/3611/
# 项目概况
# 数据类型
厦门市市民球场信息数据
# 开发环境
centos7
# 软件版本
python3.8.18、hadoop3.2.0、spark3.1.2、scala2.12.18、jdk8
# 开发语言
python、Scala
# 开发流程
数据上传(hdfs)->数据分析(spark)->可视化(pyecharts)
# 可视化图表
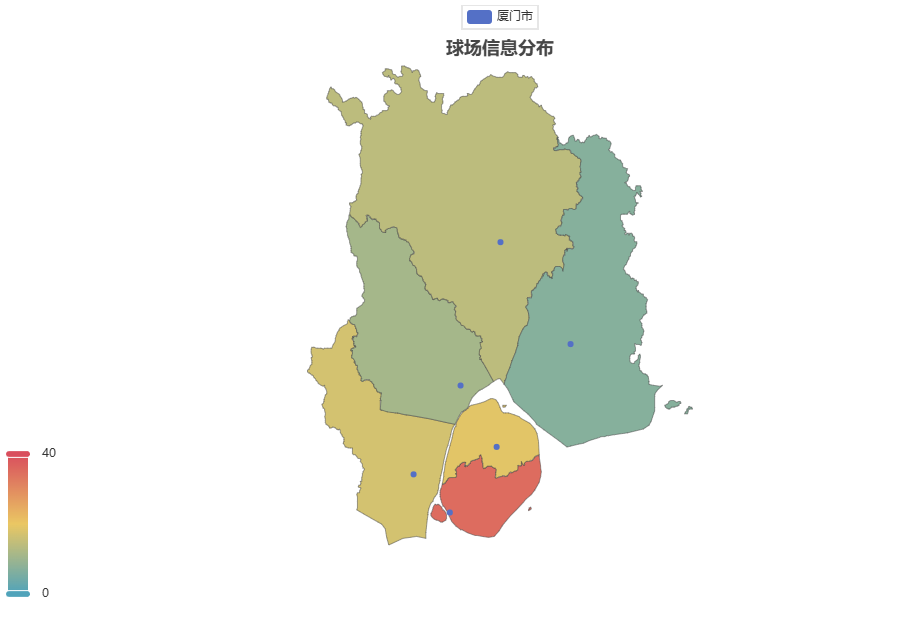
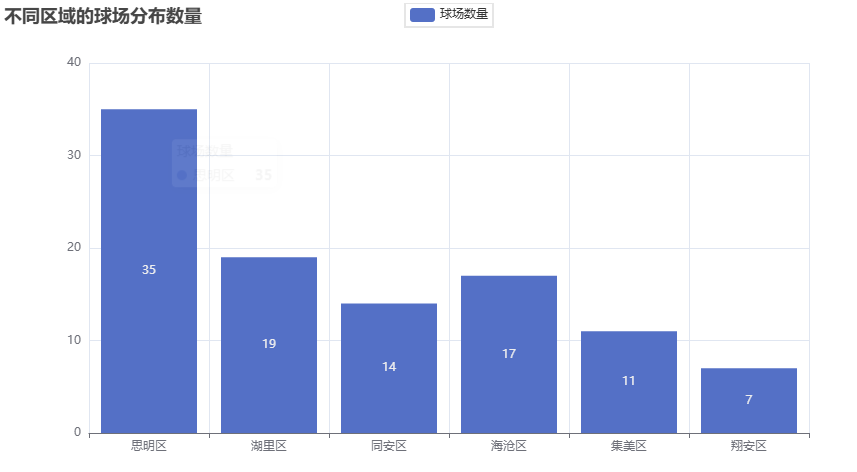
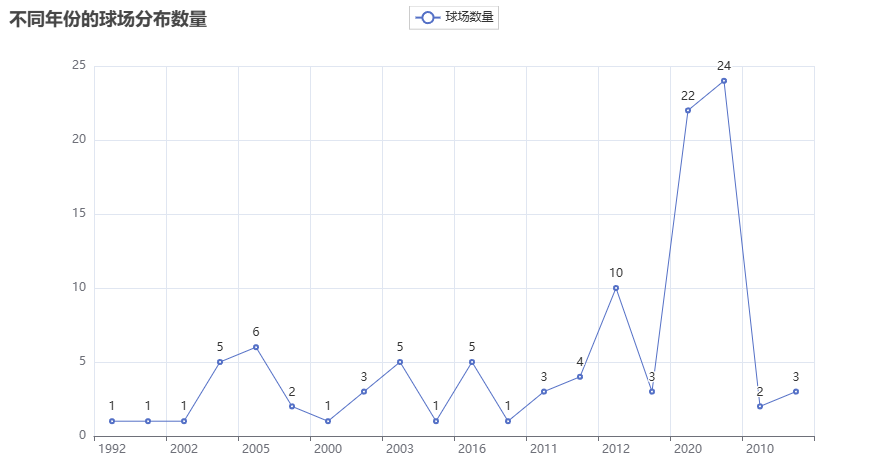
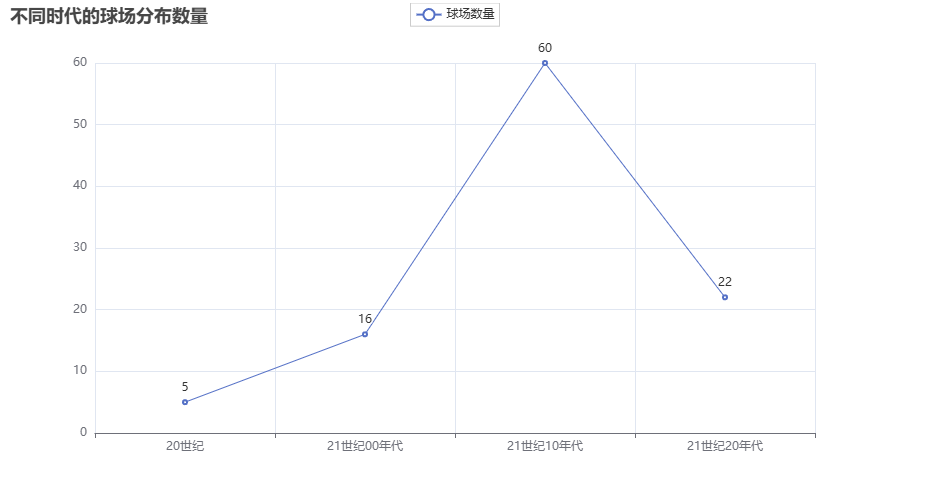
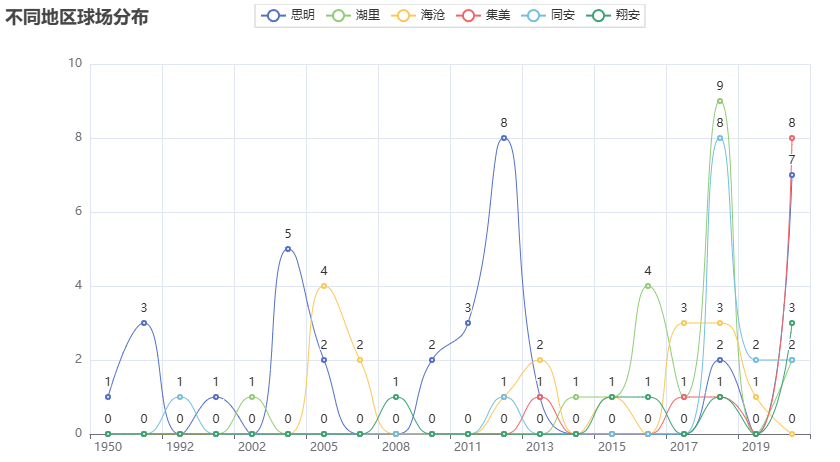
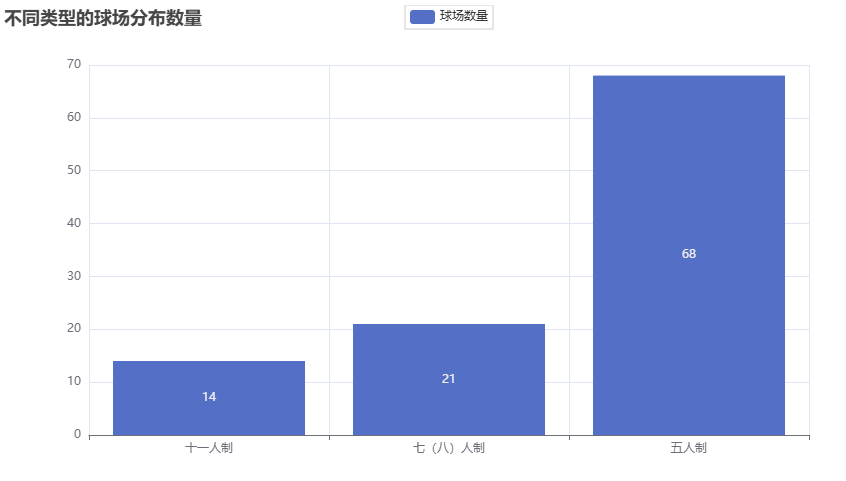
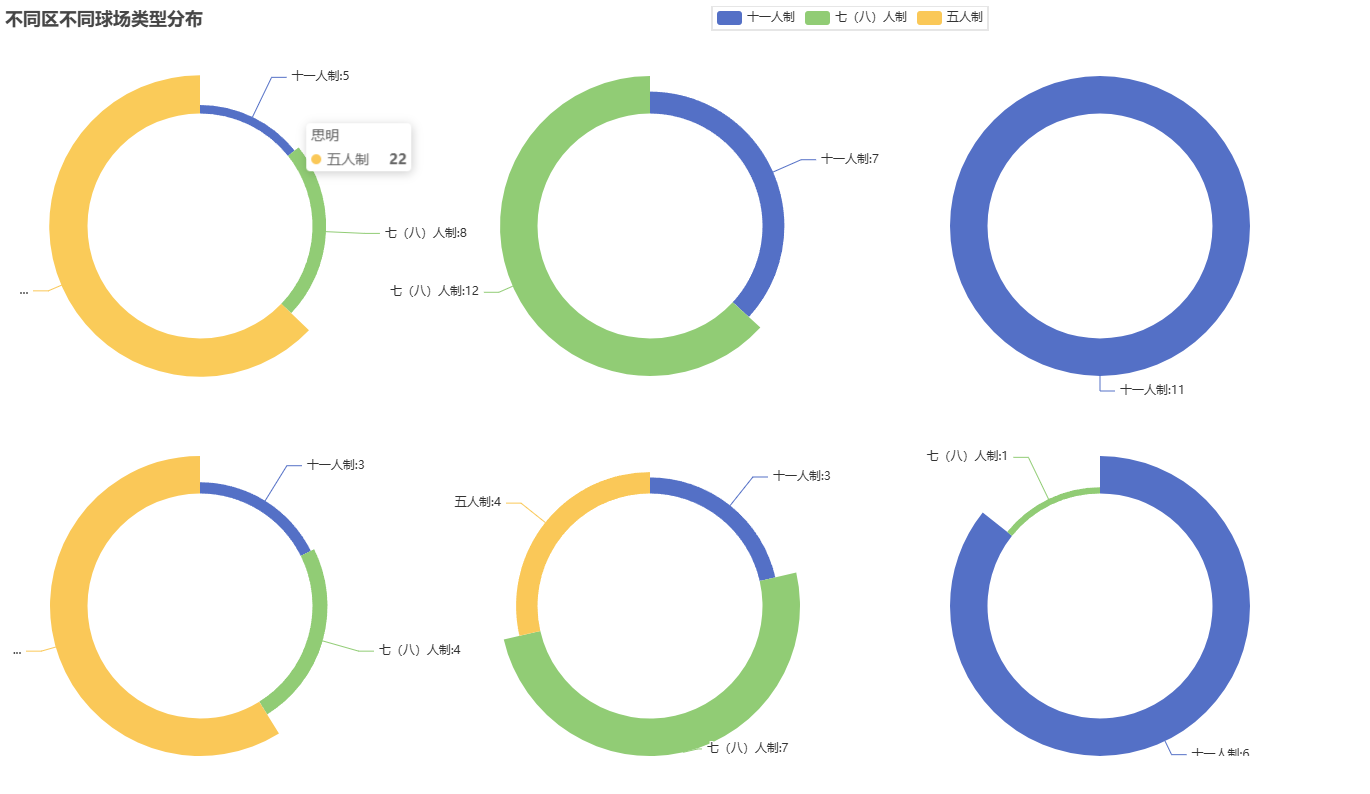
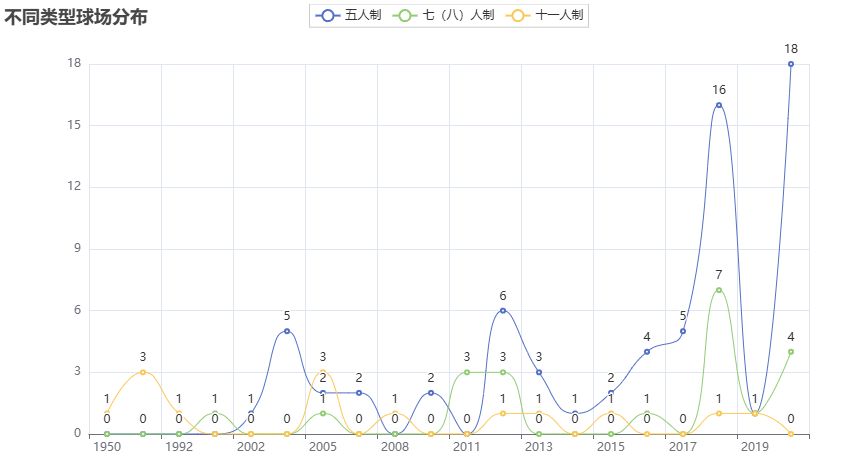
# 操作步骤
# python安装包
pip3 install pandas==2.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install flask==3.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install flask-cors==4.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install pymysql==1.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install pyecharts==2.0.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
1
2
3
4
5
6
7
2
3
4
5
6
7
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 准备目录
mkdir -p /data/jobs/project/
cd /data/jobs/project/
# 上传 "data" 目录下的 "Xiamen_civic_stadium.csv" 文件/文件夹 到 "/data/jobs/project/" 目录
1
2
3
4
5
6
2
3
4
5
6
# 上传文件到hdfs
cd /data/jobs/project/
hdfs dfs -mkdir -p /data/input/
hdfs dfs -rm -r /data/input/*
hdfs dfs -put Xiamen_civic_stadium.csv /data/input/
hdfs dfs -ls /data/input/
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 程序打包
cd /data/jobs/project/
# 对项目 "project-spark-citizen-stadium-data-analysis" 进行打包
# 打包命令: mvn clean package -DskipTests
# 上传 "project-spark-citizen-stadium-data-analysis/target/" 目录下的 "spark-job.jar" 文件 到 "/data/jobs/project/" 目录
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# spark数据分析
cd /data/jobs/project/
spark-submit \
--master local[*] \
--class com.exam.SparkApp \
/data/jobs/project/spark-job.jar /data/input/ file:///data/jobs/project/output
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 可视化
mkdir -p /data/jobs/project/myapp/
cd /data/jobs/project/myapp/
# 上传 "可视化" 目录下的 "所有" 文件和文件夹 到 "/data/jobs/project/" 目录
python3 run.py
# 生成多个html文件
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9