基于spark的澳洲光伏发电站选址预测
舟率率 7/12/2025 scalaspringbootvue
# 项目概况
# 数据类型
光伏发电站数据
# 开发环境
centos7
# 软件版本
python3.8.18、hadoop3.2.0、hive3.1.2、spark3.1.2、mysql5.7.38、scala2.12.18、jdk8、sqoop1.4.7
# 开发语言
python、Scala、Java
# 开发流程
数据上传(hdfs)->数据清洗(spark)->数据分析(spark)->机器学习(spark)->数据存储(mysql)->后端(springboot)->前端(vue)
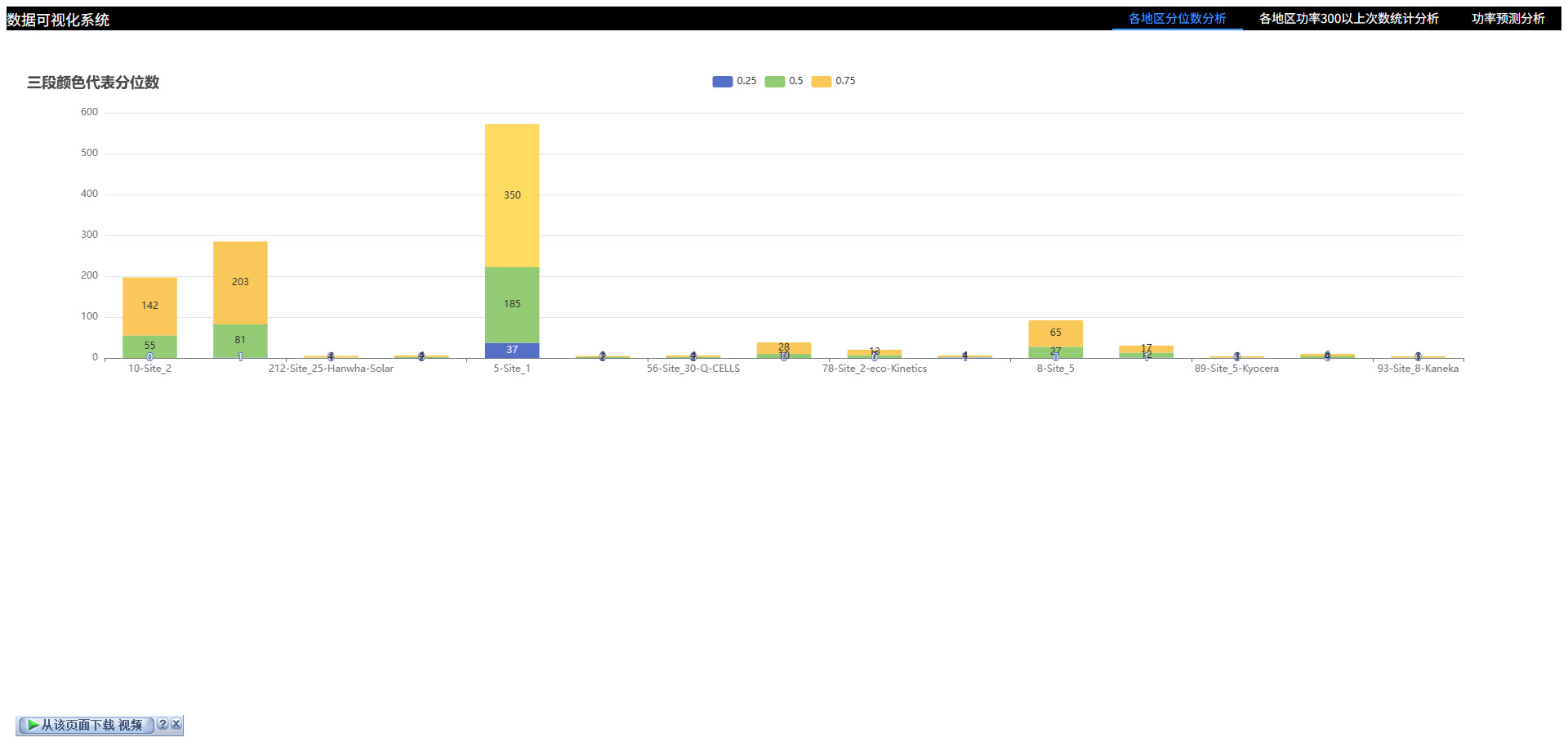
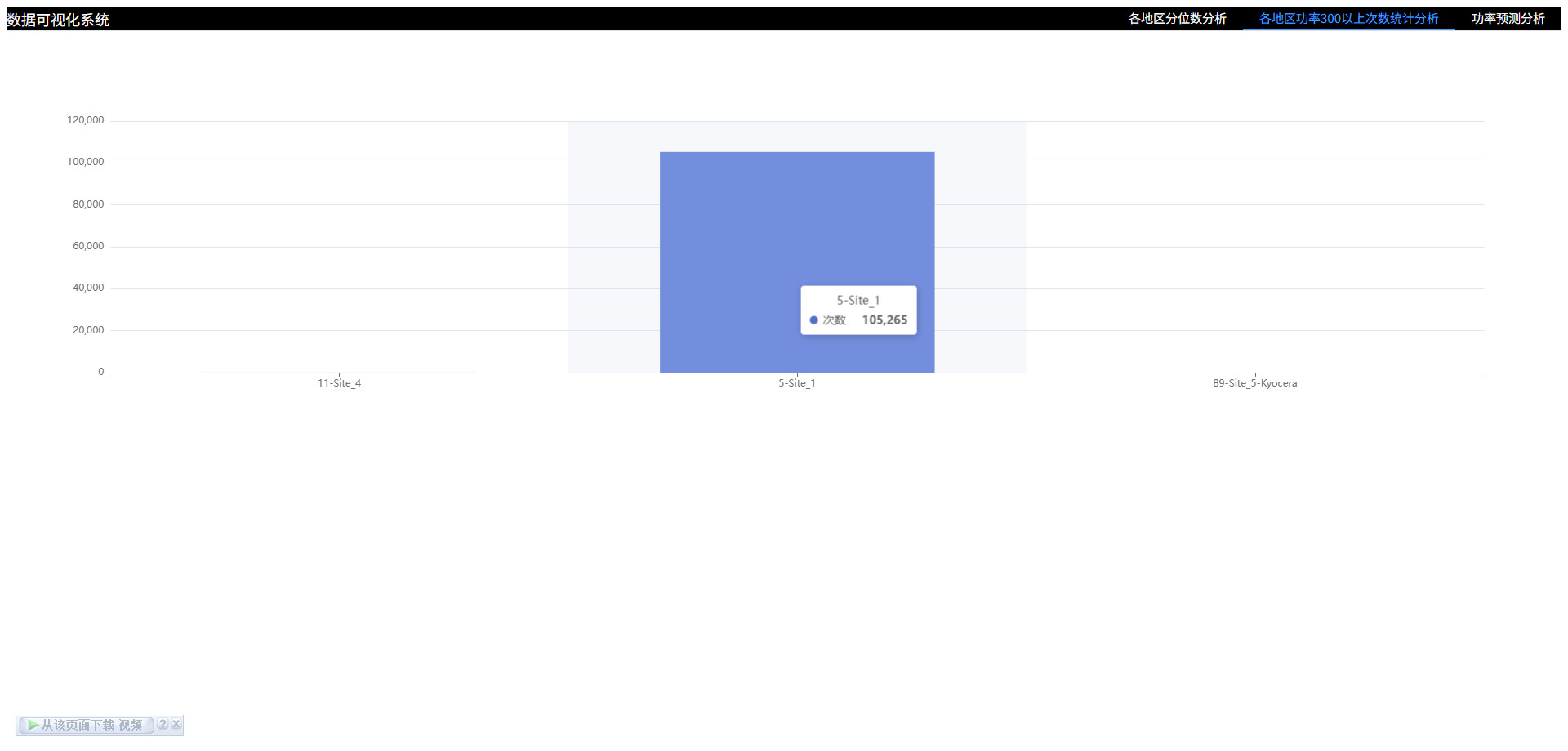
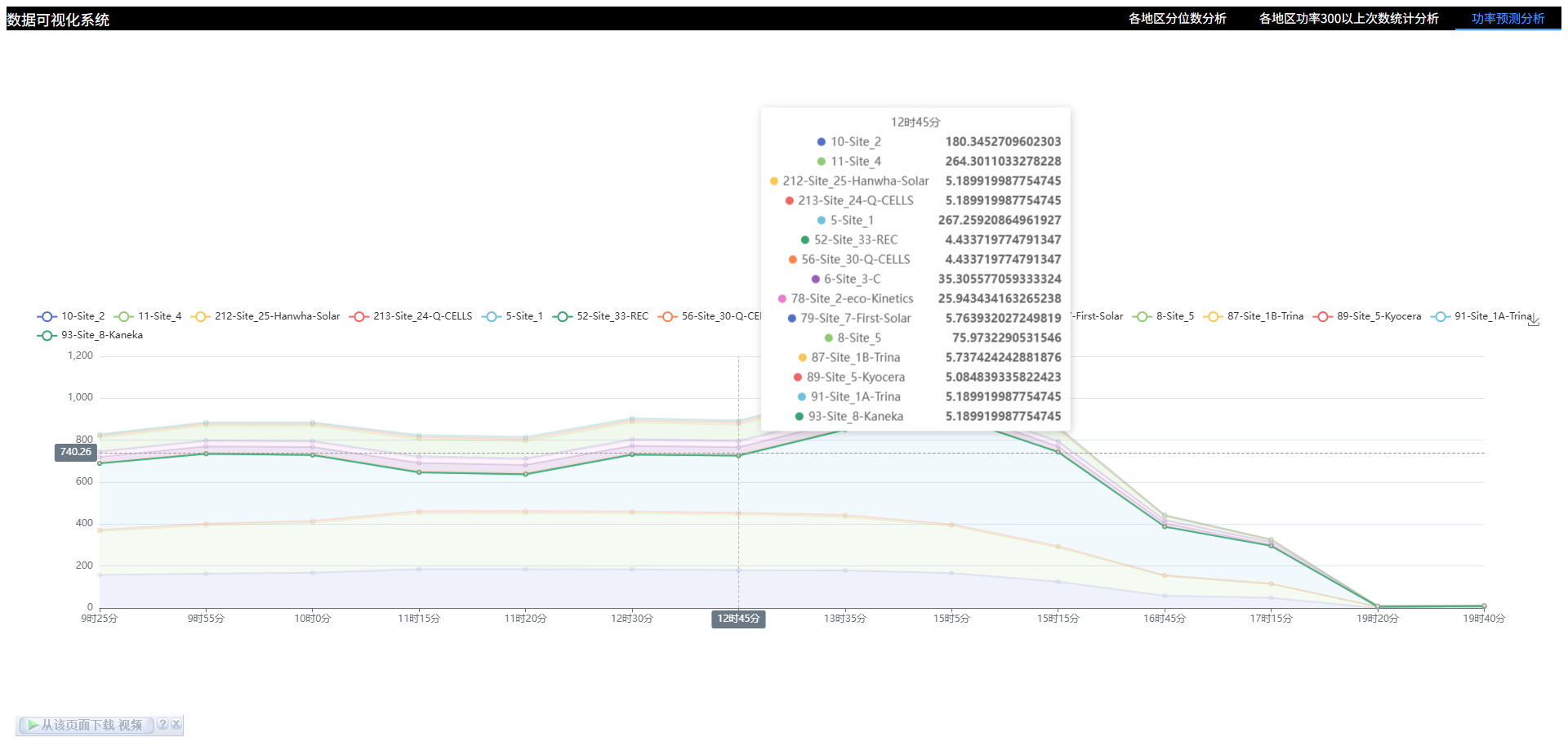
# 可视化图表
# 操作步骤
# 启动MySQL
# 查看mysql是否启动 启动命令: systemctl start mysqld.service
systemctl status mysqld.service
# 进入mysql终端
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
mysql -uroot -p123456
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 创建MySQL库
CREATE DATABASE IF NOT EXISTS recommendation CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
1
2
3
2
3
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 准备目录
mkdir -p /data/jobs/project/
cd /data/jobs/project/
# 解压 "16个地点完整光伏数据.zip"
# 上传 "16个地点完整光伏数据" 目录下 "所有" csv文件 到 "/data/jobs/project/" 目录
# 5-Site_1.csv
# 6-Site_3-C.csv
# 8-Site_5.csv
# 10-Site_2.csv
# 11-Site_4.csv
# 52-Site_33-REC.csv
# 56-Site_30-Q-CELLS.csv
# 78-Site_2-eco-Kinetics.csv
# 79-Site_7-First-Solar.csv
# 87-Site_1B-Trina.csv
# 89-Site_5-Kyocera.csv
# 91-Site_1A-Trina.csv
# 93-Site_8-Kaneka.csv
# 212-Site_25-Hanwha-Solar.csv
# 213-Site_24-Q-CELLS.csv
# 218-Site_9A-Solibro.csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 上传文件到hdfs
cd /data/jobs/project/
hdfs dfs -mkdir -p /data/input/
hdfs dfs -rm -r /data/input/*
hdfs dfs -put 5-Site_1.csv /data/input/
hdfs dfs -put 6-Site_3-C.csv /data/input/
hdfs dfs -put 8-Site_5.csv /data/input/
hdfs dfs -put 10-Site_2.csv /data/input/
hdfs dfs -put 11-Site_4.csv /data/input/
hdfs dfs -put 52-Site_33-REC.csv /data/input/
hdfs dfs -put 56-Site_30-Q-CELLS.csv /data/input/
hdfs dfs -put 78-Site_2-eco-Kinetics.csv /data/input/
hdfs dfs -put 79-Site_7-First-Solar.csv /data/input/
hdfs dfs -put 87-Site_1B-Trina.csv /data/input/
hdfs dfs -put 89-Site_5-Kyocera.csv /data/input/
hdfs dfs -put 91-Site_1A-Trina.csv /data/input/
hdfs dfs -put 93-Site_8-Kaneka.csv /data/input/
hdfs dfs -put 212-Site_25-Hanwha-Solar.csv /data/input/
hdfs dfs -put 213-Site_24-Q-CELLS.csv /data/input/
hdfs dfs -put 218-Site_9A-Solibro.csv /data/input/
hdfs dfs -ls /data/input/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 程序打包
cd /data/jobs/project/
# 对 "project-spark-station-prediction" 目录下的项目 "project-spark-station-prediction" 进行打包
# 打包命令: mvn clean package -Dmaven.test.skip=true
# 上传 "project-spark-station-prediction/target/" 目录下的 "project-spark-station-prediction-jar-with-dependencies.jar" 文件 到 "/data/jobs/project/" 目录
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# spark数据清洗
cd /data/jobs/project/
# 上传 "脚本" 目录下的 "data_clean.sh" 文件/ 到 "/data/jobs/project/" 目录
sed -i 's/\r//g' data_clean.sh
bash data_clean.sh
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# spark数据分析
cd /data/jobs/project/
# 计算不同地区有效功率大于指定值的数量
# 计算各地区的分位数
spark-submit \
--master local[*] \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 4 \
--executor-cores 1 \
--class org.example.StationAnalysisApp \
/data/jobs/project/project-spark-station-prediction-jar-with-dependencies.jar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 机器学习
cd /data/jobs/project/
spark-submit \
--master local[*] \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 4 \
--executor-cores 1 \
--class org.example.StationPredictModelApp \
/data/jobs/project/project-spark-station-prediction-jar-with-dependencies.jar
# 同样的特征,在不同位置,预测的结果对比,可以体现出哪个地区位置更加优越
spark-submit \
--master local[*] \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 4 \
--executor-cores 1 \
--class org.example.StationPredictOneApp \
/data/jobs/project/project-spark-station-prediction-jar-with-dependencies.jar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 启动后端
# 已安装 "jdk8" 和 "maven" 环境
# 启动springboot
# 打包命令: mvn clean package -Dmaven.test.skip=true
# 入口类: org.apophis.Application
1
2
3
4
5
6
7
2
3
4
5
6
7
# 启动前端
使用hdfs dfs -rm -r /user/example/test删除目录后,立刻上传,不一定能成功,因为文件流未完全关闭,需要等一会儿
# 已安装 "node" 环境
# 启动前端
npm install --registry=https://registry.npmmirror.com
npm run dev
1
2
3
4
5
6
7
2
3
4
5
6
7