基于hive的大学硕士研究生录取数据分析与可视化
舟率率 6/7/2025 pythonmapreduceflasksqoophbasejava
# 项目概况
# 数据类型
学生成绩及复试成绩数据
# 开发环境
centos7
# 软件版本
python3.8.18、hadoop3.2.0、hive3.1.2、mysql5.7.38、jdk8、sqoop1.4.7、hbase2.2.7
# 开发语言
python、Java
# 开发流程
数据预处理(java)->数据存储(hbase)->文件上传(hdfs)->数据分析(hive)->数据分析(mapreduce)->数据存储(mysql)->后端(flask)->前端(html+js+css)
# 可视化图表
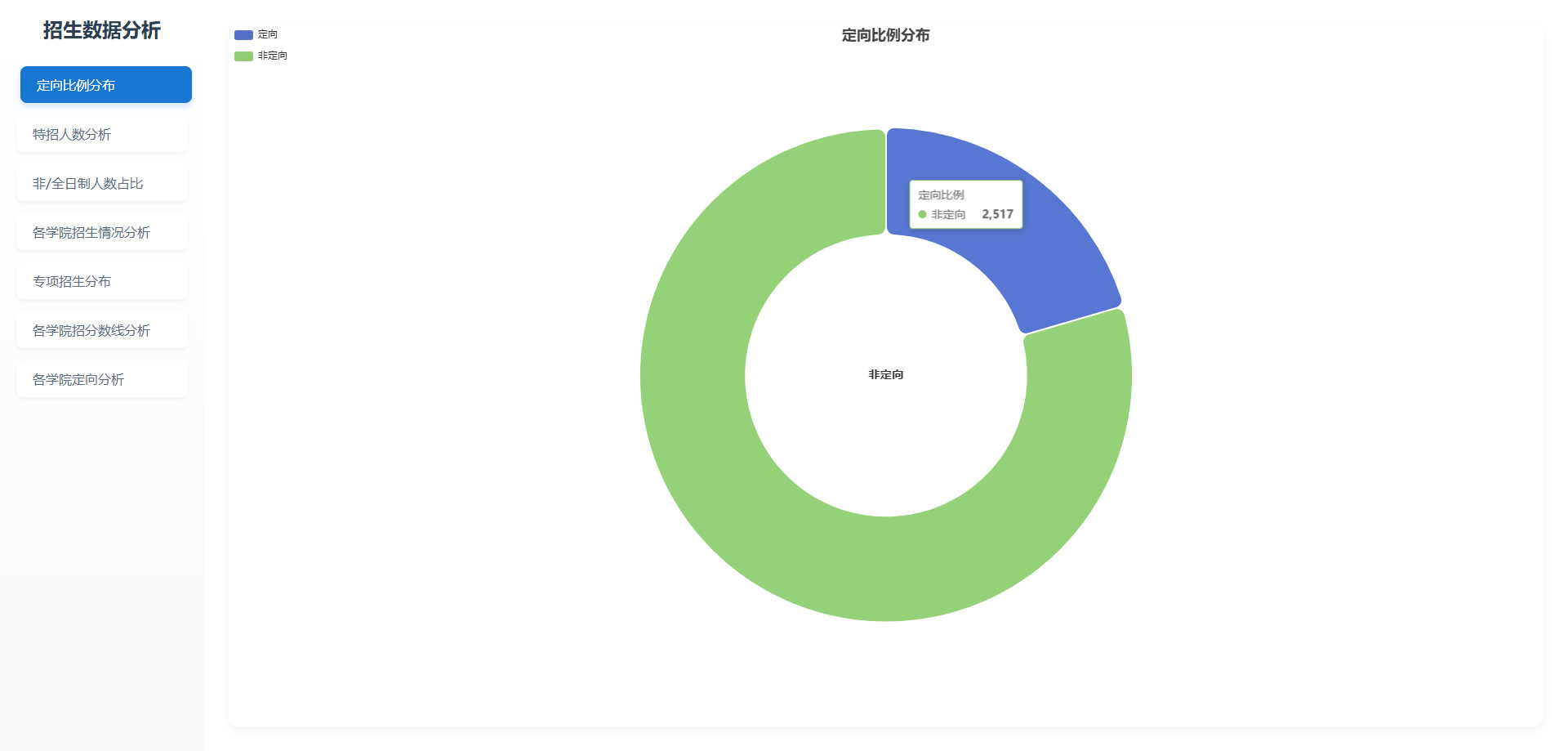
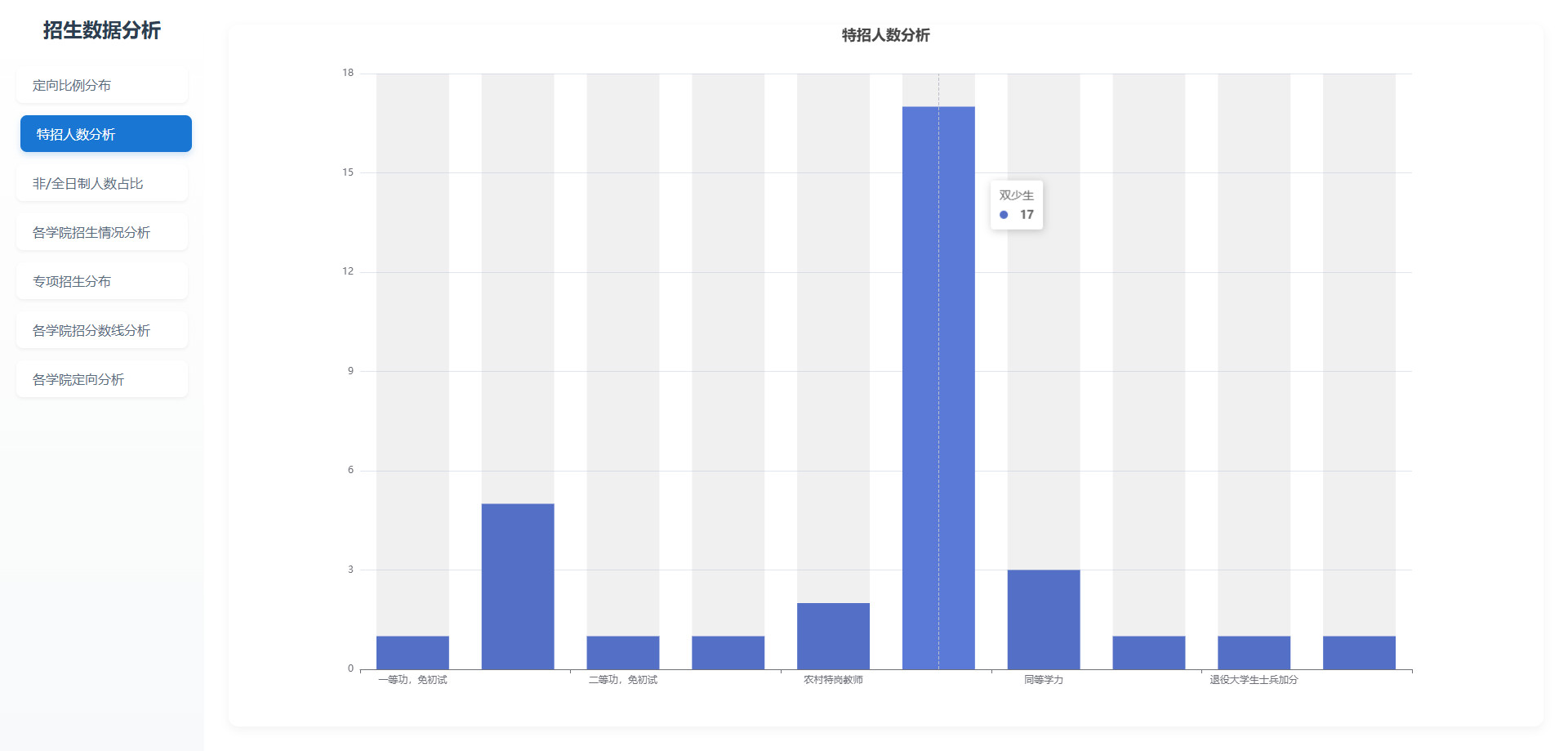
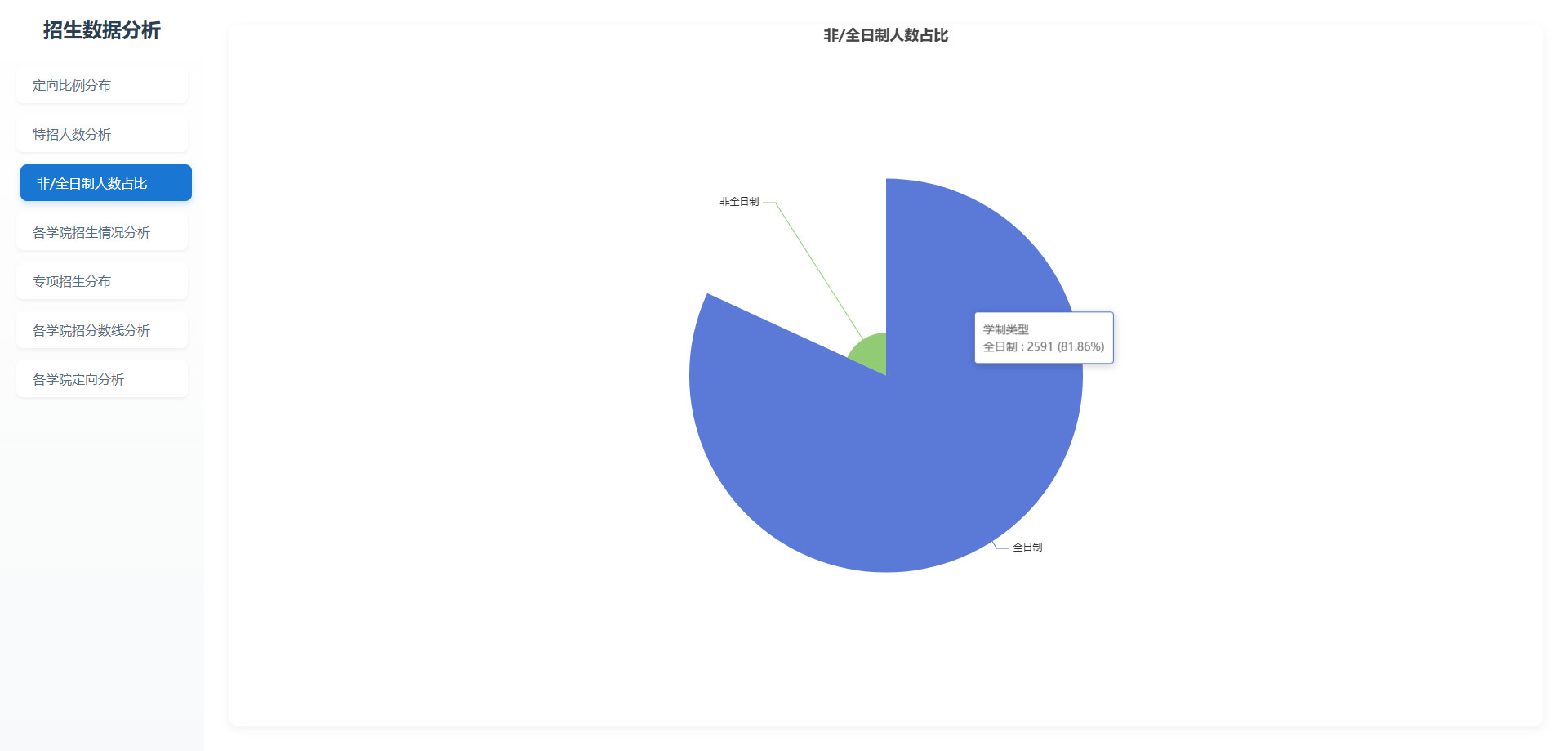
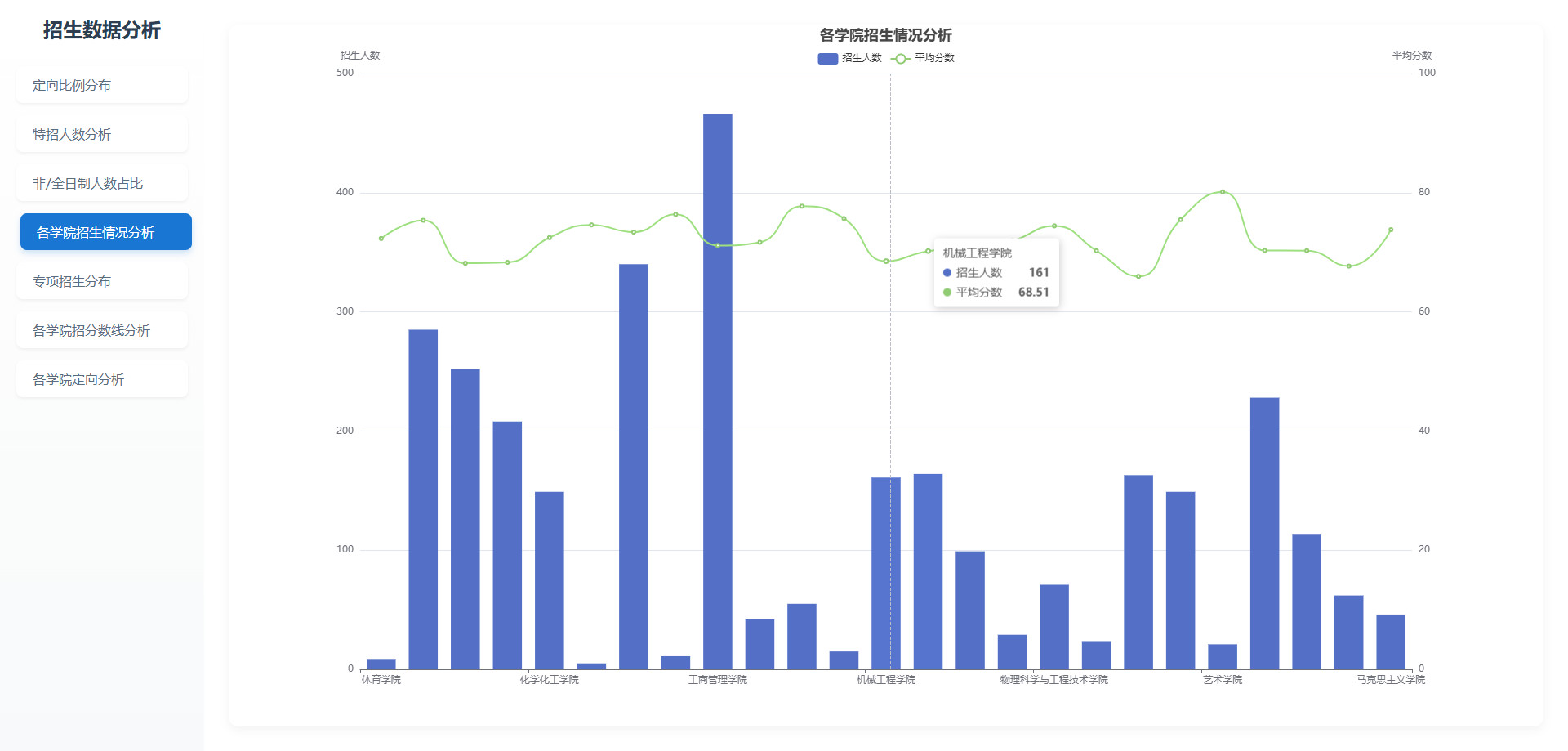
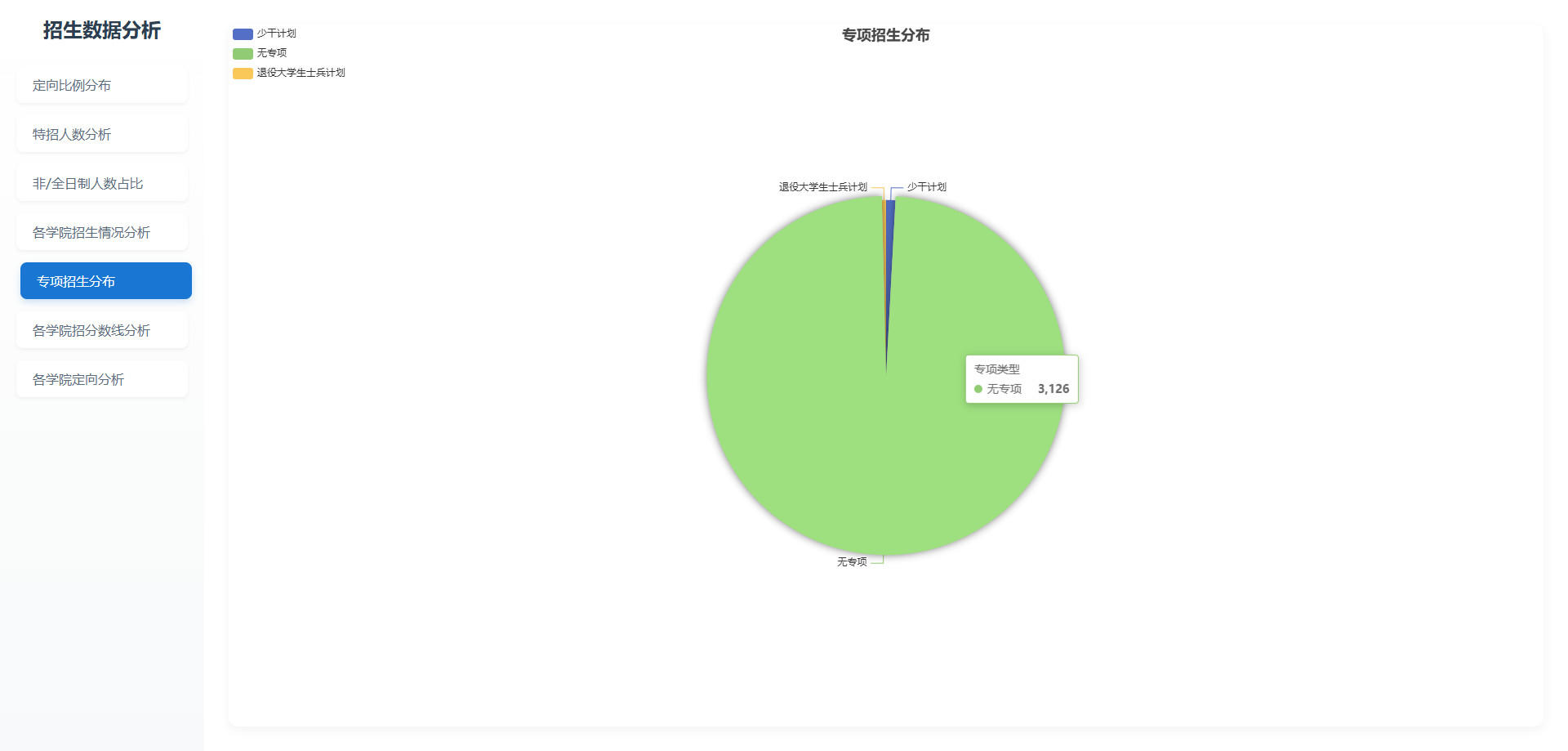
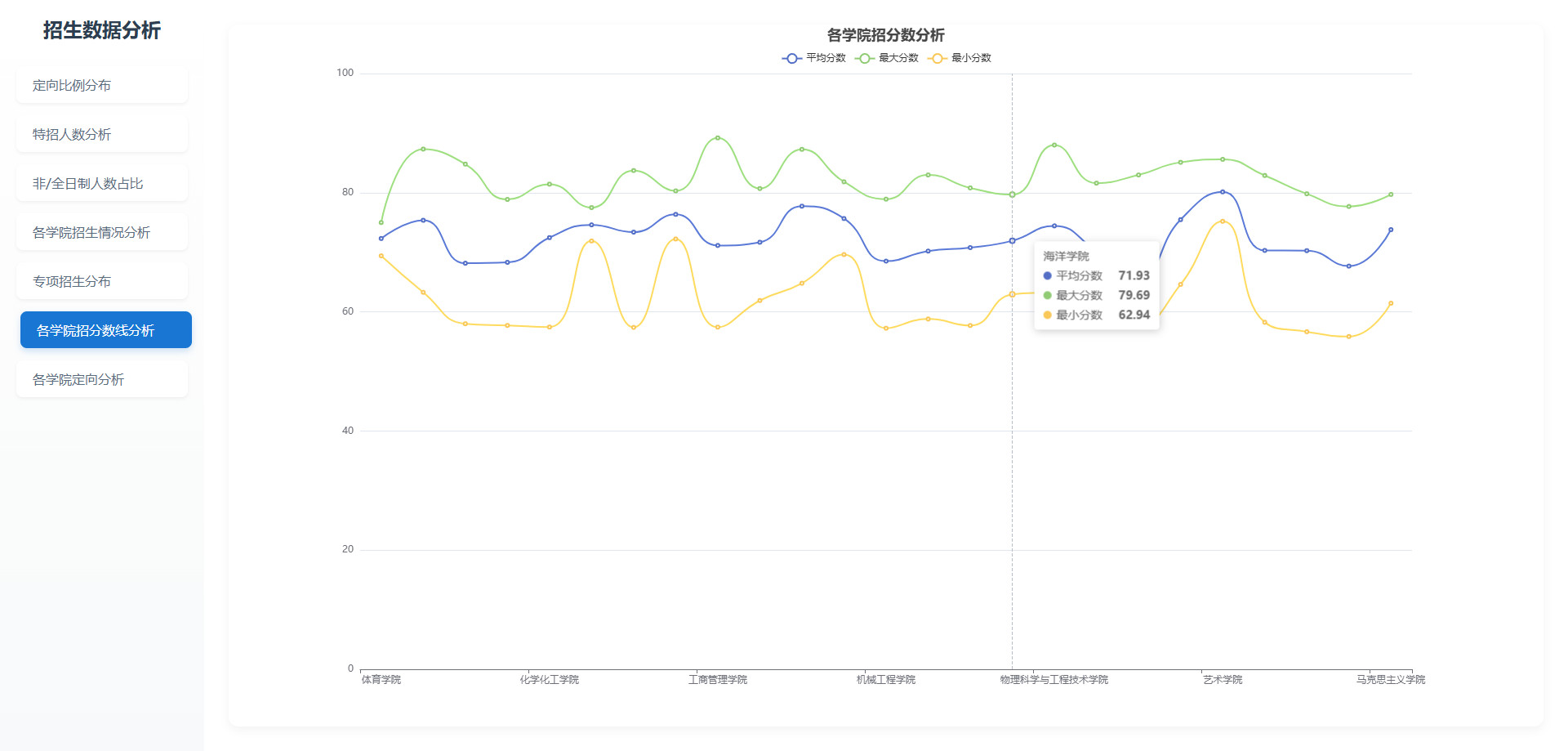
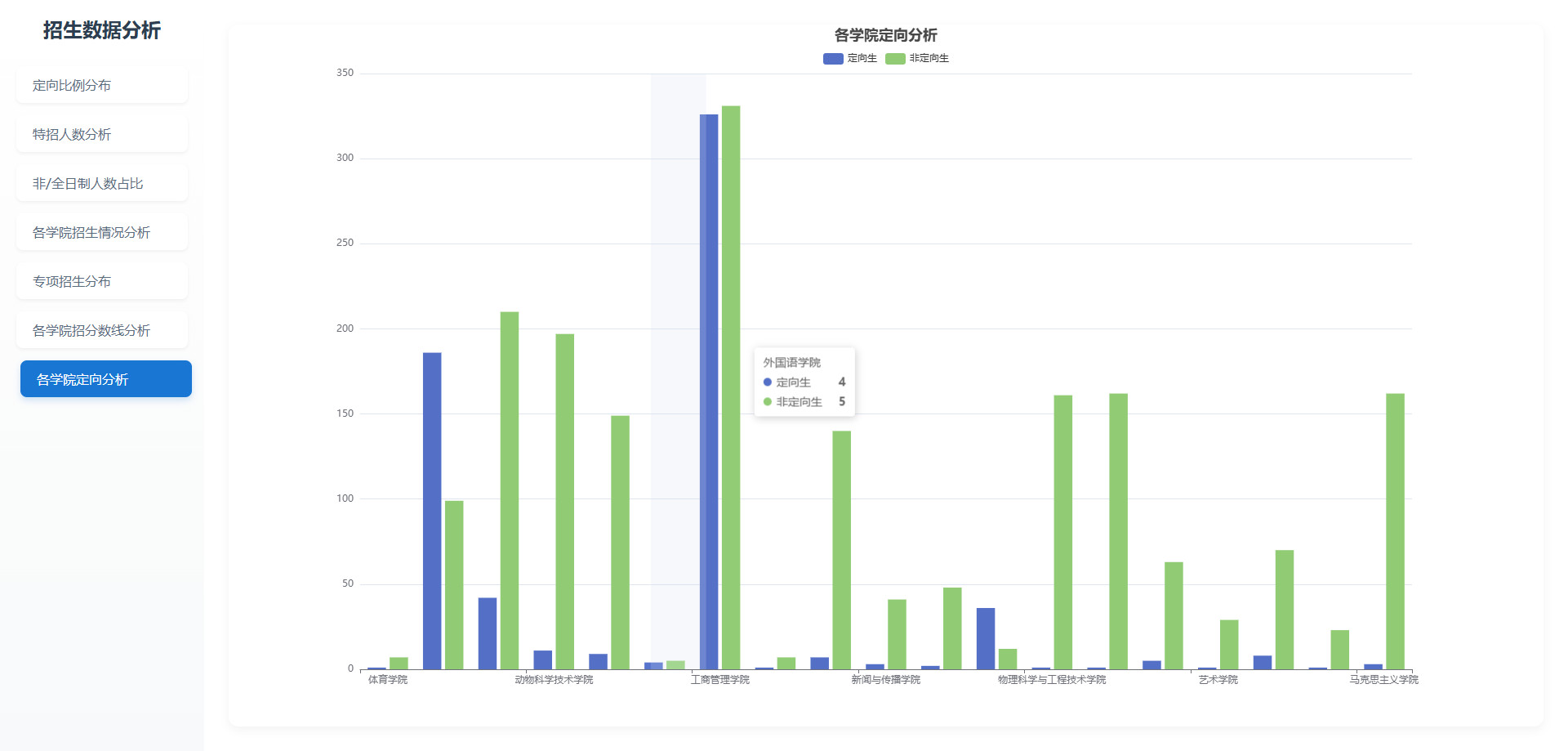
# 操作步骤
# python安装包
pip3 install pandas==2.0.3 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install flask==3.0.0 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install flask-cors==4.0.1 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install pymysql==1.1.0 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install bottle==0.12.25 -i https://pypi.tuna.tsinghua.edu.cn/simple
1
2
3
4
5
6
7
2
3
4
5
6
7
# 启动MySQL
# 查看mysql是否启动 启动命令: systemctl start mysqld.service
systemctl status mysqld.service
# 进入mysql终端
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
# MySQL的用户名:root 密码:123456
mysql -uroot -p123456
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
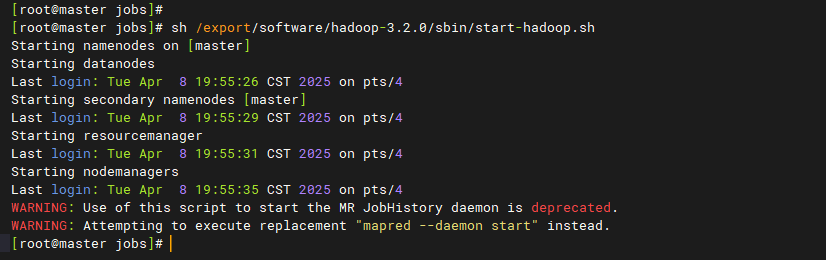
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 启动hive
# 在第一个窗口中,执行后等待10-20秒
/export/software/apache-hive-3.1.2-bin/bin/hive --service metastore
# 在第二个窗口中,执行后等待10-20秒
/export/software/apache-hive-3.1.2-bin/bin/hive --service hiveserver2
# 连接进入hive终端命令如下:
# /export/software/apache-hive-3.1.2-bin/bin/beeline -u jdbc:hive2://master:10000 -n root
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10

# 启动hbase
# 启动zookeeper
/export/software/apache-zookeeper-3.6.4-bin/bin/zkServer.sh start
# 开启hbase
sh /export/software/hbase-2.2.7/bin/start-hbase.sh
# 进入hbase shell
/export/software/hbase-2.2.7/bin/hbase shell
# 关闭hbase
sh /export/software/hbase-2.2.7/bin/stop-hbase.sh
# 关闭zookeeper
/export/software/apache-zookeeper-3.6.4-bin/bin/zkServer.sh stop
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
# 程序打包
mkdir -p /data/jobs/project/
cd /data/jobs/project/
# 上传 "noproject-hbase-mapreduce-hive" 整个文件夹
# 使用打包命令完成对 "noproject-hbase-mapreduce-hive" 的项目打包
# 打包命令
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
mvn clean package -Dmaven.test.skip=true
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
# 将 "mapreduce-job-jar-with-dependencies.jar" 复制到 "/data/jobs/project/" 目录
rm -f mapreduce-job-jar-with-dependencies.jar
cp mapreduce-job/target/mapreduce-job-jar-with-dependencies.jar .
# 将 "write-to-hbase-jar-with-dependencies.jar" 复制到 "/data/jobs/project/" 目录
rm -f write-to-hbase-jar-with-dependencies.jar
cp write-to-hbase/target/write-to-hbase-jar-with-dependencies.jar .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 数据预处理
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
# 原数据分隔符全是空格,使用程序判断各数值所属字段,并定义分隔符\t
java -cp write-to-hbase-jar-with-dependencies.jar org.example.write.hbase.DataClean
# 查看 "output/" 的结果
ls -l output/
head -10 output/复试成绩.txt
head -10 output/学生总成绩.txt
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 数据存入hbase
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
# 将 "output/" 目录下的数据,写入hbase
java -cp write-to-hbase-jar-with-dependencies.jar org.example.write.hbase.WriteHbase
# 使用命令进入hbase shell终端,进行校验: /export/software/hbase-2.2.7/bin/hbase shell
# get 'student_scores','1',{FORMATTER => 'toString'}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 重命名及上传文件
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
mv output/学生总成绩.txt output/stu_scores.txt
mv output/复试成绩.txt output/repeat.txt
ls -l output/
# 上传到hdfs
hdfs dfs -mkdir -p /data/input/
hdfs dfs -rm -r /data/input/*
hdfs dfs -put output/repeat.txt /data/input/
hdfs dfs -ls /data/input/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# hive数据分析
cd /data/jobs/project/noproject-hbase-mapreduce-hive/hive数据分析/
# 连接进入hive终端命令如下:
# /export/software/apache-hive-3.1.2-bin/bin/beeline -u jdbc:hive2://master:10000 -n root
# 快速执行hive.sql
hive -v -f hive.sql
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# mapreduce数据分析
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
hadoop jar mapreduce-job-jar-with-dependencies.jar /data/input/ /data/output/
# 验证结果
hdfs dfs -ls /data/output/
hdfs dfs -cat /data/output/part-r-00000
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 创建MySQL表
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
# 请确认mysql服务已经启动了
# 快速执行.sql文件内的sql语句
mysql -u root -p < mysql.sql
1
2
3
4
5
6
7
2
3
4
5
6
7
# 数据导入MySQL
cd /data/jobs/project/noproject-hbase-mapreduce-hive/
sed -i 's/\r//g' sqoop.sh
bash sqoop.sh
1
2
3
4
5
6
2
3
4
5
6
# 启动可视化
mkdir -p /data/jobs/project/myapp/
cd /data/jobs/project/myapp/
# 上传 "可视化" 目录下的 "所有" 文件和文件夹
# windows本地运行: python app.py
python3 app.py pro
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9