基于Flink的人体肥胖数据分析_无前后端
舟率率 6/5/2025 python
原地址:https://dblab.xmu.edu.cn/post/5419/
# 项目概况
# 数据类型
开放的人体肥胖数据
# 开发环境
centos7
# 软件版本
python3.8.18、hadoop3.2.0、flink1.14.6、jdk8
# 开发语言
python
# 开发流程
数据预处理(python)->数据上传(hdfs)->数据分析(flink)->静态可视化(matplotlib)
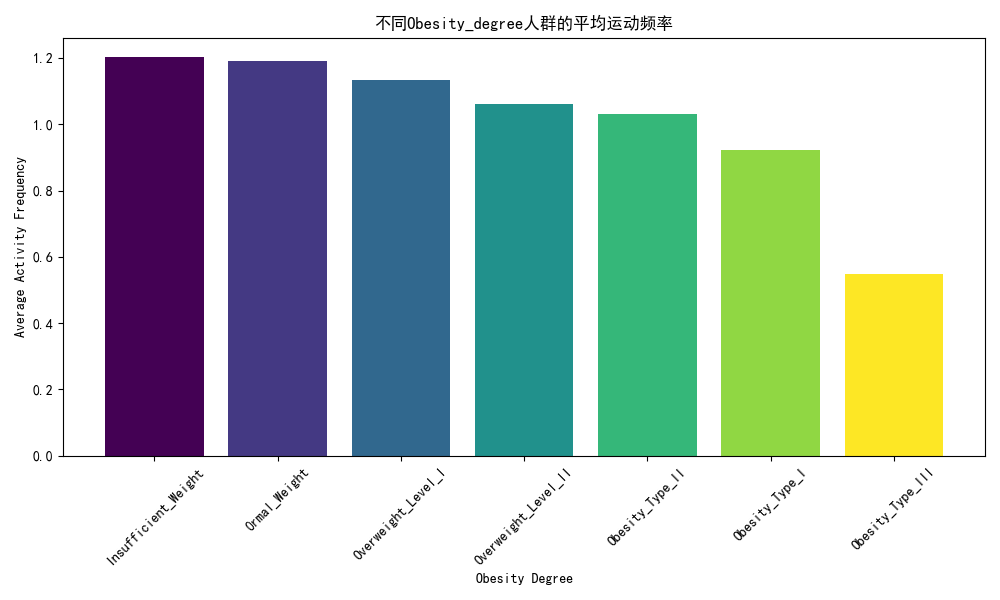
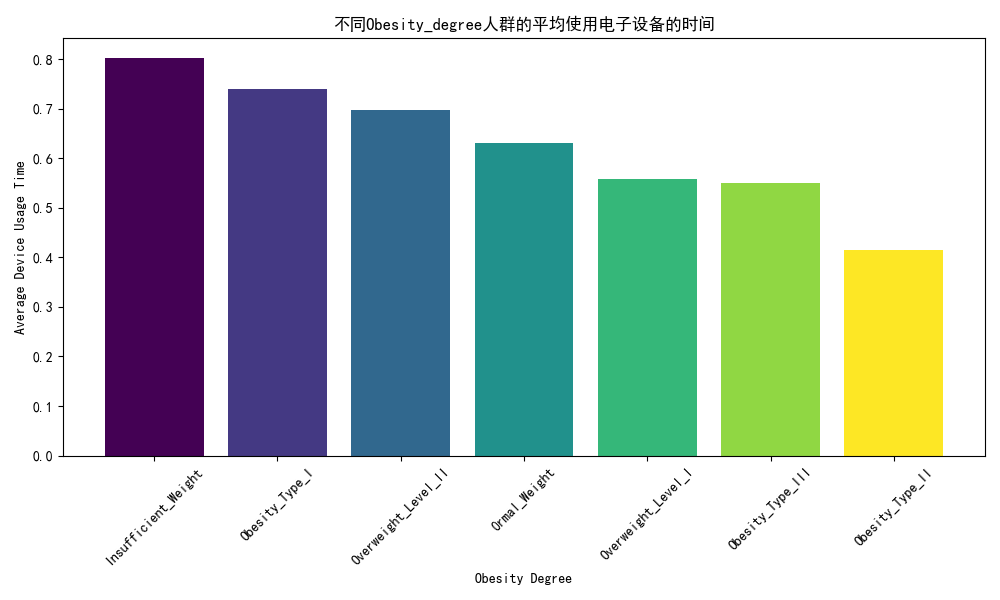
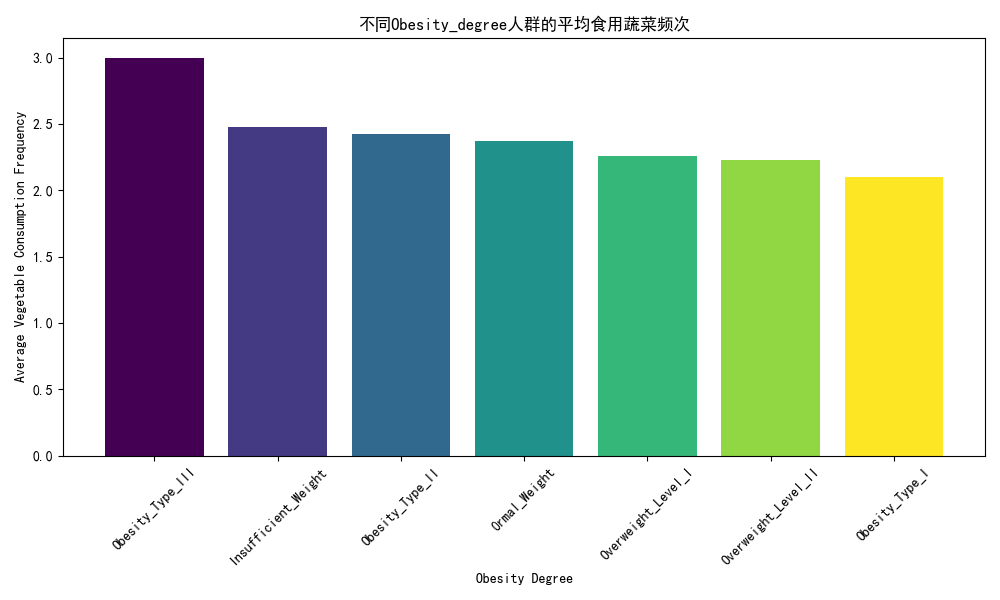
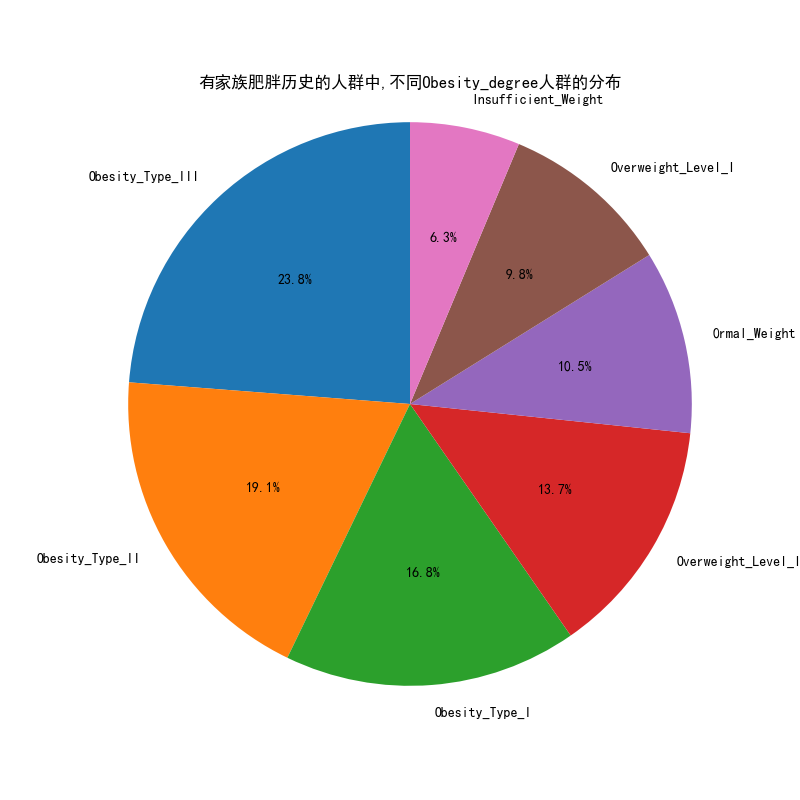
# 可视化图表
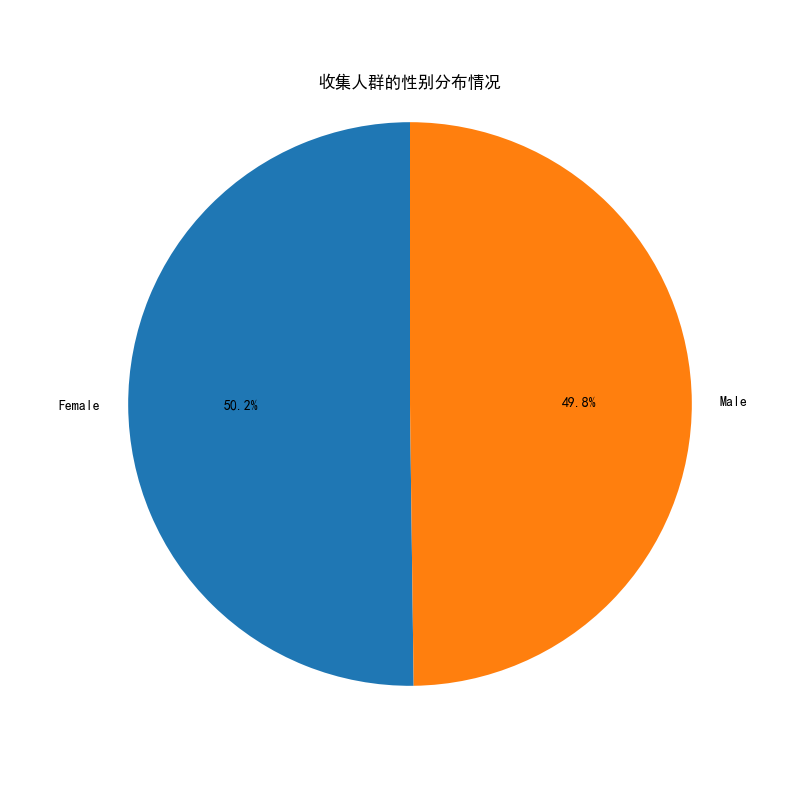
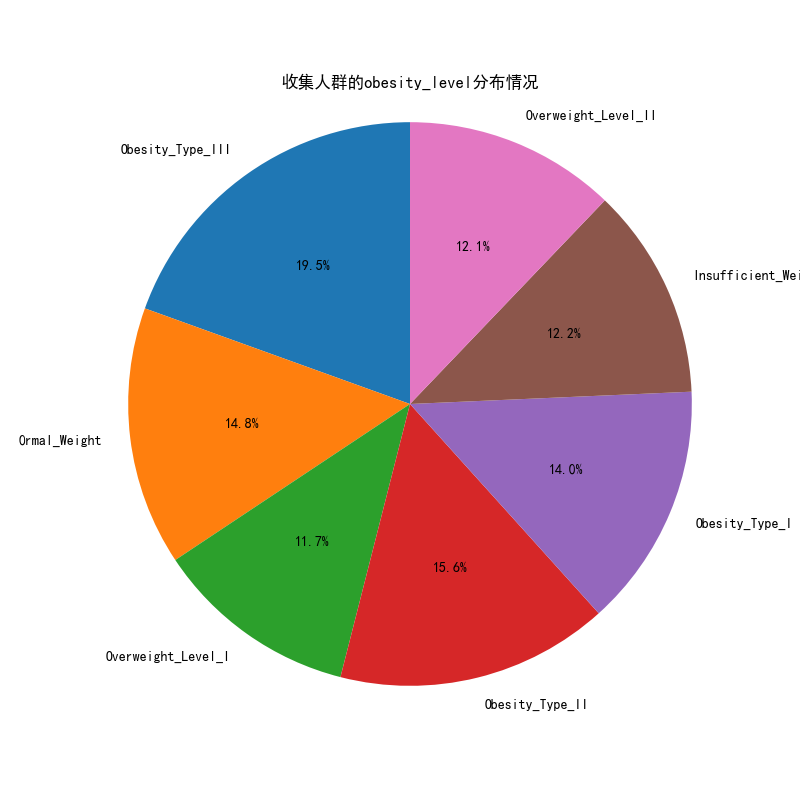
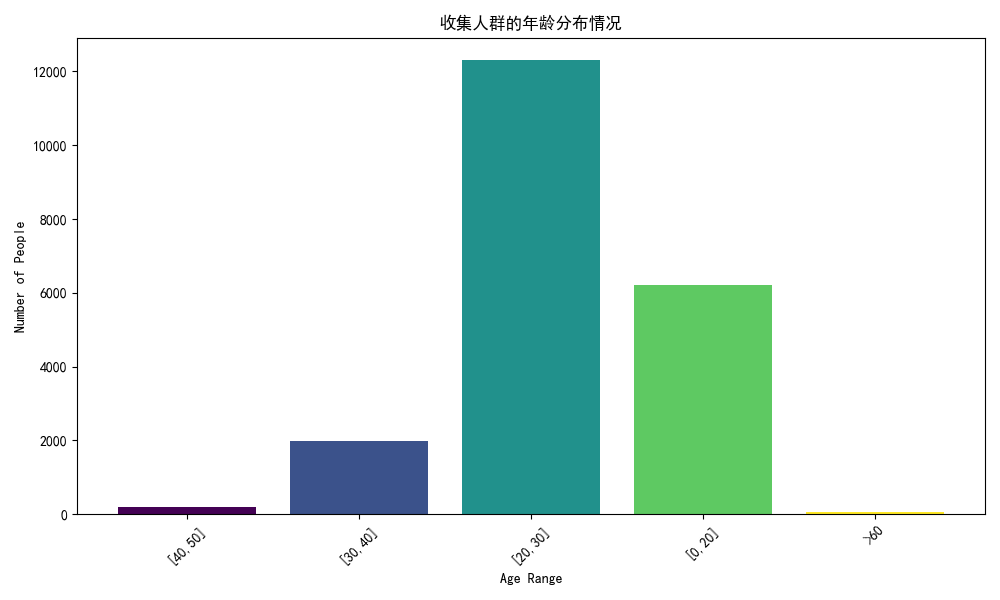
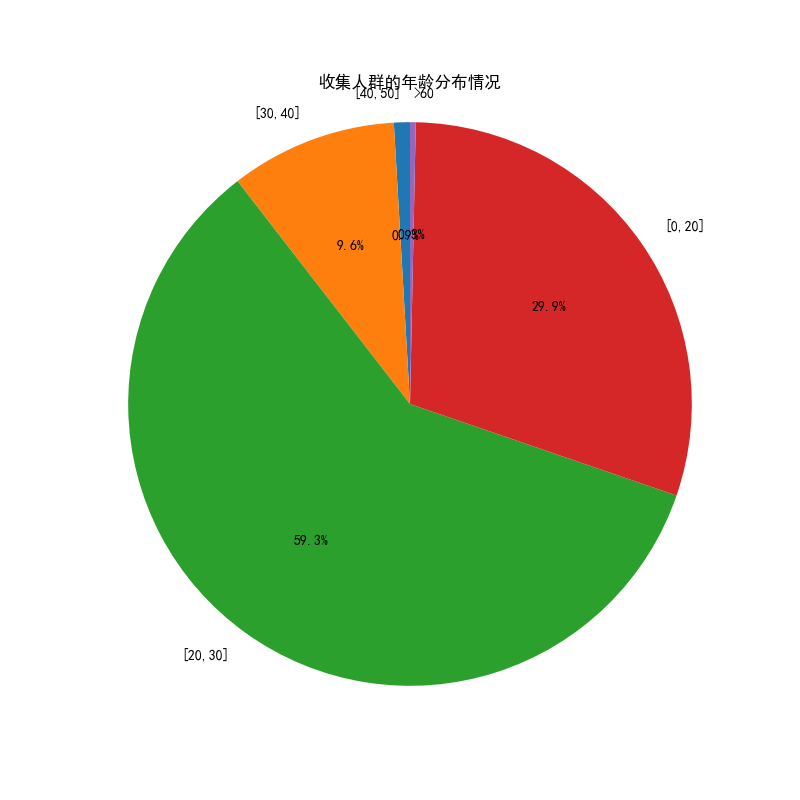
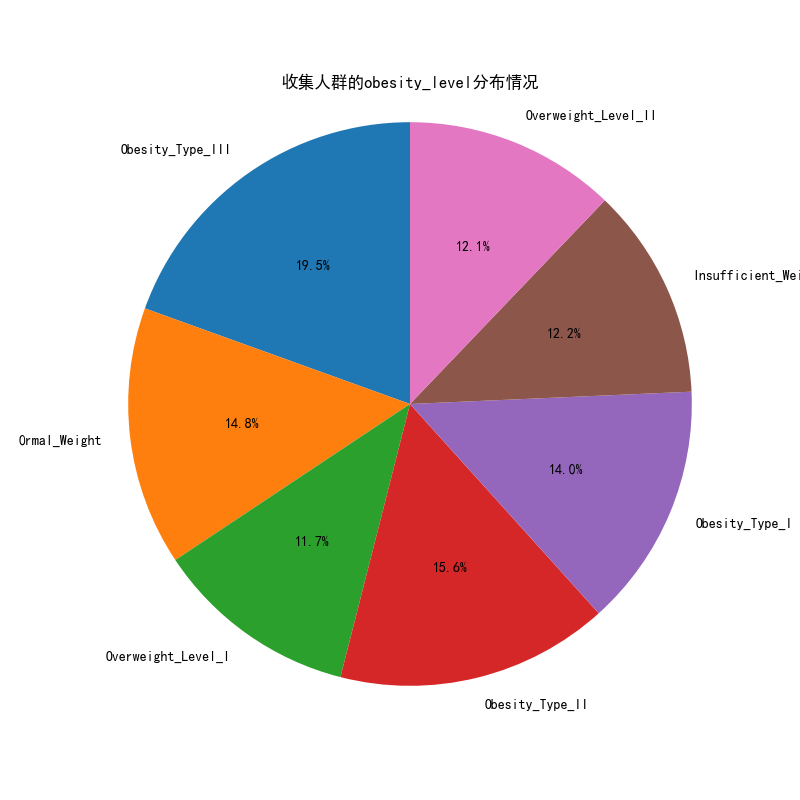
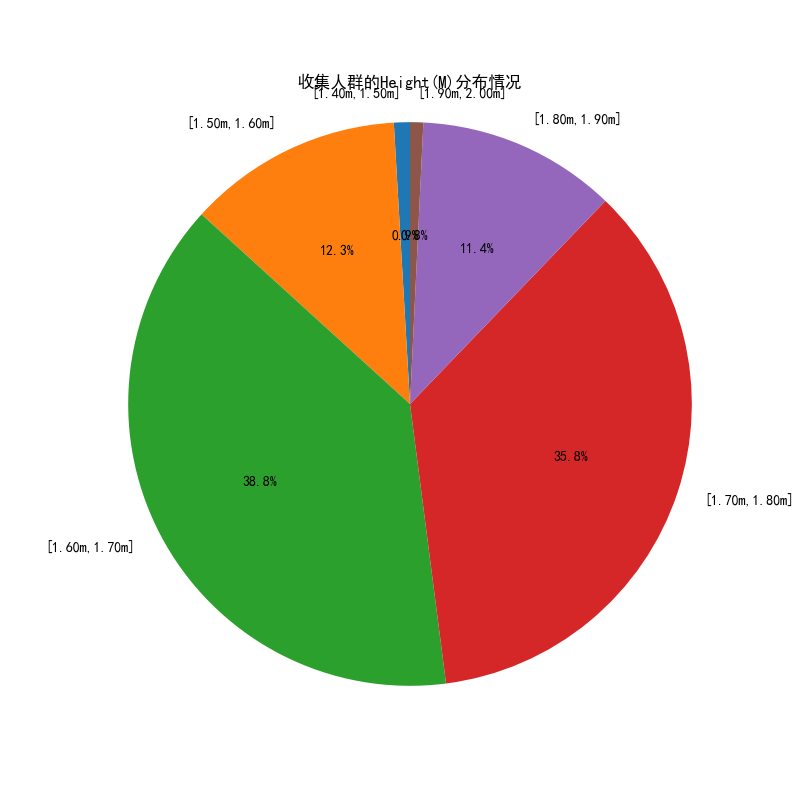
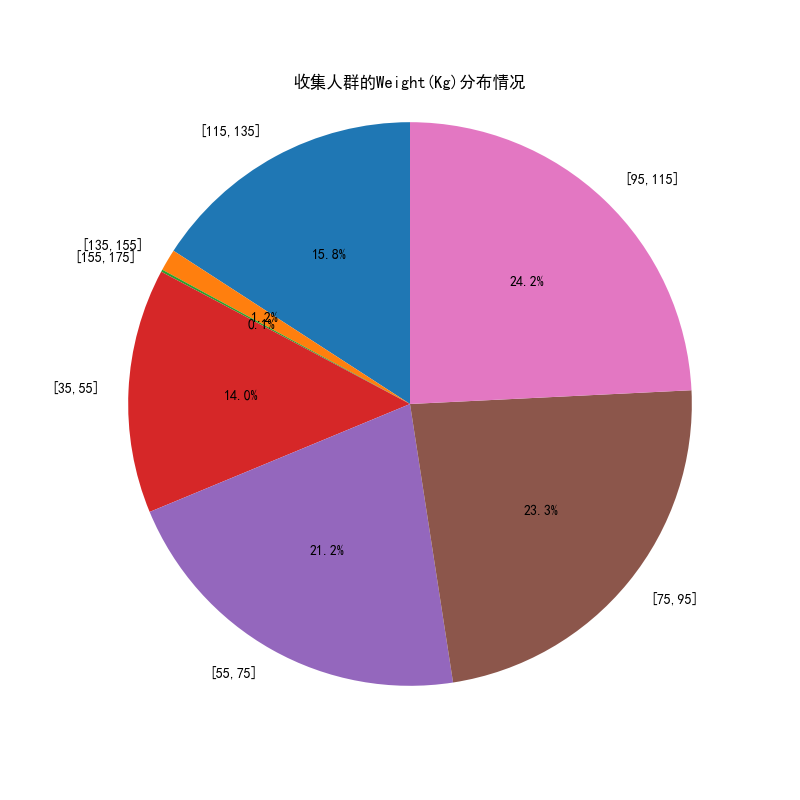
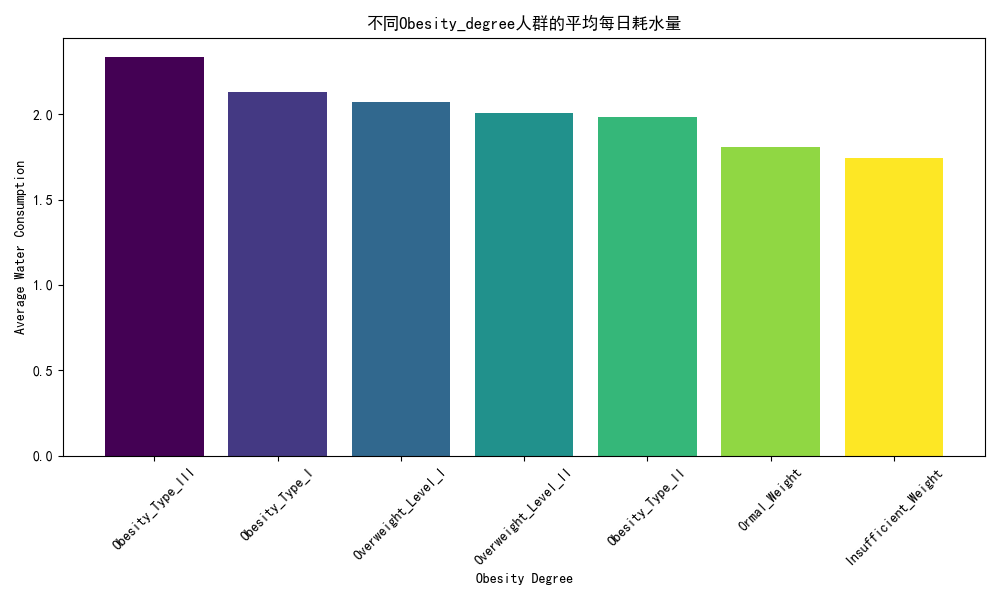
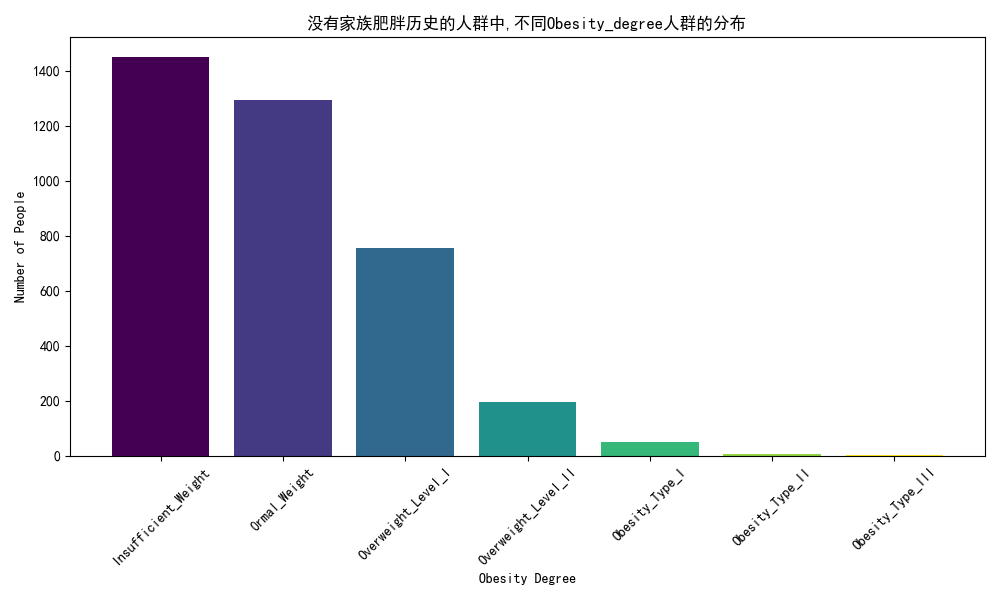
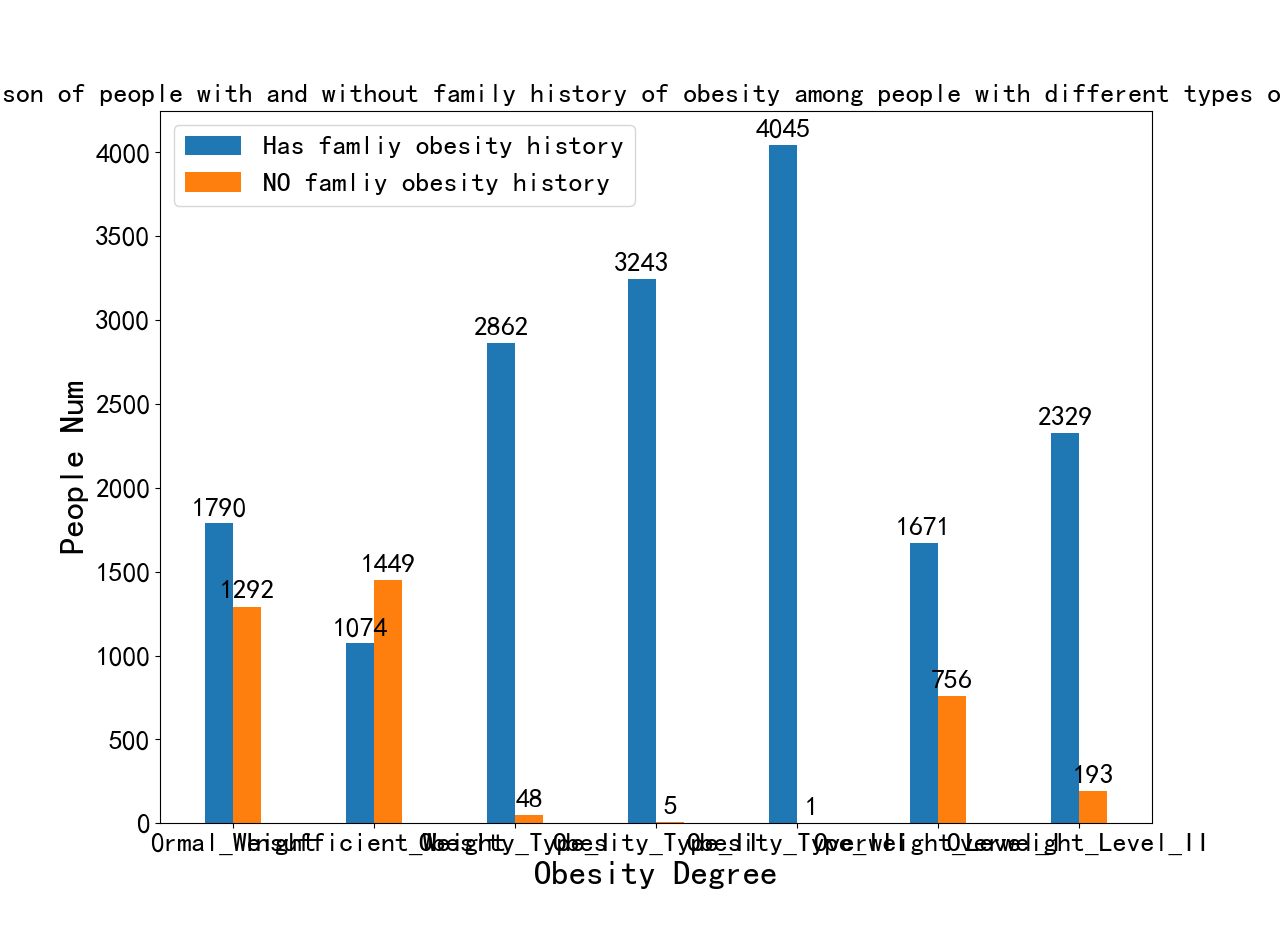
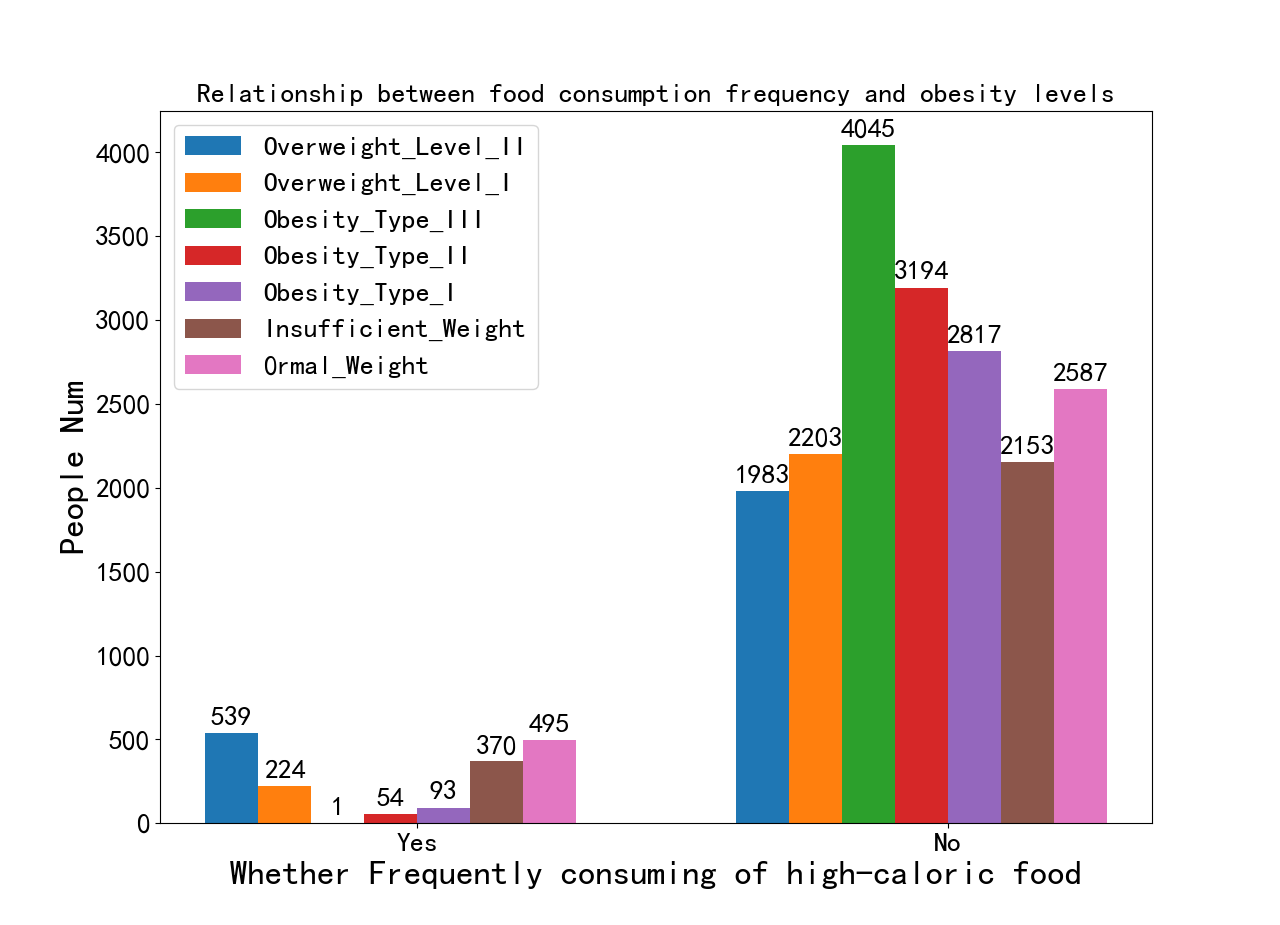
# 操作步骤
# python安装包
pip3 install apache-flink==1.14.6 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install pandas==2.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install argparse==1.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip3 install matplotlib==3.7.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install numpy==1.24.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
1
2
3
4
5
6
7
2
3
4
5
6
7
# 启动Hadoop
# 离开安全模式: hdfs dfsadmin -safemode leave
# 启动hadoop
bash /export/software/hadoop-3.2.0/sbin/start-hadoop.sh
1
2
3
4
5
2
3
4
5
# 数据集上传
# 创建目录
mkdir -p /data/jobs/project/
# 进入目录
cd /data/jobs/project/
# 解压 obesity_level.7z
# 上传 obesity_level.csv 到 /data/jobs/project/ 目录下
# 上传 data_clean.py 到 /data/jobs/project/ 目录下
# 上传 pyflink_analysis.py 到 /data/jobs/project/ 目录下
# 上传 merge.py 到 /data/jobs/project/ 目录下
# 上传 draw_picture.py 到 /data/jobs/project/ 目录下
# 查看前面5条记录
head -5 obesity_level.csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 数据预处理
cd /data/jobs/project/
python3 data_clean.py
head -10 preprocessed_obesity_level.csv
1
2
3
4
5
6
7
2
3
4
5
6
7
# 数据上传hdfs
cd /data/jobs/project/
# 上传到hdfs
hdfs dfs -mkdir -p /data/input/
hdfs dfs -rm -r /data/input/*
hdfs dfs -put preprocessed_obesity_level.csv /data/input/
hdfs dfs -ls /data/input/
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# flink数据分析
cd /data/jobs/project/
python3 pyflink_analysis.py --input hdfs://master:9000/data/input/preprocessed_obesity_level.csv
# 合并文件,方便后面可视化读取
python3 merge.py
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 生成静态可视化网页
python3 draw_picture.py
1
2
3
2
3